本文得到了原英文作者Shakir Mohamed的授权同意,由钟琰翻译、何通审校。感谢他们的支持和帮助。
基于前馈深度神经网络的判别模型已经在许多工业应用中获得了成功,引发了探寻如何利用无监督学习方法带来相似结果的热潮。降噪自动编码器是深度学习中一种主要的无监督学习方法。本文将探索降噪自编码器和统计学中密度估计之间的联系,我们将从统计学的视角去考察降噪自动编码器学习方法,并将之视为一种潜在因子模型的推断问题。我们的机器学习应用能从这样的联系中获得启发并受益。
广义的降噪自动编码器(GDAEs)
降噪自动编码器是无监督深度学习中的一个重大进步,它极大的提升了数据表示的可扩展性和稳健性。对每个数据点y,降噪自动编码器先利用一个已知的噪化过程$\mathcal{C}(\mathbf{y}’|\mathbf{y})$建立一个$\mathbf{y}$的含噪声版本$\mathbf{y}’$,其后我们以$\mathbf{y}’$为输入利用神经网络来重新恢复原始数据$\mathbf{y}$。整个学习网络可以被分为两个部分:编码器和解码器,其中编码器$\mathbf{z}$的输出可被认为是原始数据的一种表示或特征。该问题的目标函数如下^[Pascal Vincent, Hugo Larochelle, Yoshua Bengio, Pierre-Antoine Manzagol,Extracting and composing robust features with denoising autoencoders, Proceedings of the 25th international conference on Machine learning, 2008]:
$$\textrm{Perturbation:}\quad \mathbf{y}’ \sim\mathcal{C}(\mathbf{y}’|\mathbf{y})$$
$$\textrm{Encoder:}\quad \mathbf{z(y’)} = f_\phi (\mathbf{y’})\qquad\textrm{Decoder:}\quad \mathbf{y} \approx g_\theta (\mathbf{z})$$
$$\textrm{Objective:}\quad\mathcal{L}_{DAE} = \log p(\mathbf{y} |\mathbf{z})$$
其中$\log p(\cdot)$是一个依数据选择的对数似然函数,同时目标函数是所有观测点上对数似然函数的平均。广义降噪自编码器(GDAEs)考虑到这个目标函数受制于有限的训练数据,从而在原有公式的基础上引入了一个额外的惩罚项$\mathcal{R}(\cdot)$^[Yoshua Bengio, Li Yao, Guillaume Alain, Pascal Vincent, Generalized denoising auto-encoders as generative models, Advances in Neural Information Processing Systems, 2013]:
$$\quad\mathcal{L}_{GDAE} = \log p(\mathbf{y} |\mathbf{z}) – \lambda \mathcal{R}(\mathbf{y, y’})$$
GDAEs方法的原理是观测空间上的扰动能增强编码器结果$\mathbf{z}$的稳健性和不敏感性。使用GDAEs时,我们需要注意两个关键的问题:1)如何选择一个符合实际的噪化过程;2)如何选择合适的调整函数$\mathcal{R}(\cdot)$。
分离模型与推断
从统计上推导自编码器的困难在于:它们并不能区分数据模型(反映我们对数据性质和结构的预期的统计假设)和推断估计方法(我们将观测数据联系到模型假设的种种方法)。自编码器学习框架提供的是一套计算流程,而非统计解释。当我们要解释一个数据的时候,我们必须先了解数据再把它用作为输入。不区分数据模型和推断方法阻碍了我们去正确地评价并比较几种候选方法的好坏,让我们无法理解文献中那些能带来启发的相关方法,使我们难以利用学术界广阔的知识。
为了减轻这些忧虑,我们不妨将通过把解码器看做是统计模型(实践中确实有很多自编码器的解释与应用)来重新理解自编码器。一个概率解码器能提供数据的生成性描述,而我们的任务是对这个模型进行学习(或者推断)。对一个给定的模型,有很多可以用来进行推断的候选方法,如最大似然方法(ML),最大后验概率估计(MAP),噪声对比估计,马尔可夫链蒙特卡尔理论(MCMC),变分推断,腔方法(cavity methods),集成的嵌套拉普拉斯近似(INLA)等。因此编码器的角色便十分明确:编码器是对由解码器描述的模型进行推断的机制,它仅仅是现有的各式各样的推断方法中的一种,并且具有自己的优缺点。
潜因子模型中的近似推理
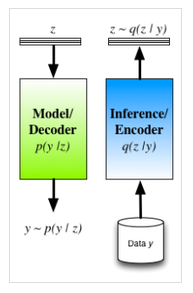
图1 潜变量模型中编码器-解码器的推断过程
另一个DAEs的难点在于它的稳健性建立在对考察原始数据的干扰上。这样一个噪化过程一般并不容易设计。此外,通过对概率分布的推导,我们可以发现通过对对数噪化数据的密度函数$\log p(\mathbf{y}’)$应用变分原理,我们可以得到DAE的目标函数$\mathcal{L}_{DAE}$的一个下界^[Pascal Vincent, Hugo Larochelle, Yoshua Bengio, Pierre-Antoine Manzagol,Extracting and composing robust features with denoising autoencoders, Proceedings of the 25th international conference on Machine learning, 2008],然而并不是我们所感兴趣的统计量。
一个可行的方法是将变分原理应用到我们感兴趣的统计量上来,即对数观测数据的边际概率分布$\log p(\mathbf{y})$^[Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra, Stochastic Backpropagation and Approximate Inference in Deep Generative Models, Proceedings of The 31st International Conference on Machine Learning, 2014] ^[Diederik P Kingma, Max Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114, 2014]。通过将变分原则应用到生成模型(概率解码器模型)中能够得到新的目标函数,我们称其为变分自由能:
$$\mathcal{L}_{VFE} = \mathbb{E}_{q(\mathbf{z})}[ \log p(\mathbf{y} | \mathbf{z})] – KL[q(\mathbf{z}) \|p(\mathbf{z})]$$
仔细观察公式,我们可以发现它和GDAE的目标函数相符合。不过这里仍然存在着以下几点显著的不同:
1)不同于考虑观测值上的扰动,该公式考虑在隐藏值上通过$\mathbf{z}$的先验分布$p\mathbf{(z)}$获得的扰动。这时隐藏层变量是随机隐变量,而自编码器是一个可以用来直接抽样的生成模型。
2)编码器$q\mathbf{(z|y)}$用来近似潜变量的真实后验分布$p\mathbf{(z|y)}$。
3)我们现在可以从理论上解释GDAE目标函数中引入的惩罚函数。与其人为设计惩罚项,我们更应该推导出这个惩罚函数的形式应该是先验概率与编码器分布之间的KL距离。
从这个视角再次考察自编码器,可以看到它是一种近似贝叶斯推断的高效实现。利用一个编码器-解码器的结构,我们可以使用单个计算模型来优化所有参数。由于对测试数据仅需要一次前向计算,该方法能够让我们快速有效地进行统计推断。使用这种方法的代价是我们将面临一个更难的最优化问题,因为优化编码器的参数让我们同时耦合所有潜变量的推断。那些不把q分布作为一个编码器的方法可以处理观测数据中的任意缺失值,而我们的编码器必须在已知缺失值模式的情况下进行训练,没有办法处理观测数据中任意缺失模式。我们使用的一种探究这个联系的方法是在深度隐高斯模型(DLGM)中基于随机变分推断(并利用一个编码器进行实现)^[Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra, Stochastic Backpropagation and Approximate Inference in Deep Generative Models, Proceedings of The 31st International Conference on Machine Learning, 2014]进行统计推断,这种方法现在是一系列扩展内容的基础^[Diederik P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, Max Welling, Semi-supervised learning with deep generative models, Advances in Neural Information Processing Systems, 2014] ^[Karol Gregor, Ivo Danihelka, Alex Graves, Daan Wierstra, DRAW: A Recurrent Neural Network For Image Generation, arXiv preprint arXiv:1502.04623, 2015]。
总结
自动编码器能够用来解决统计推断的问题,并为统计推断提供了一个强而有力的方法,这一方法将在寻找更好的非监督学习方法中起到重要作用。使用统计学视角看待自编码器,并使用变分法对其重塑,使得我们能很好地区分统计模型和推断方法。于是我们能更有效地实现推断,得到一个易于抽样的生成模型,这允许我们研究所关心的统计量,并得到一个有重要惩罚项的损失函数。这是一个将会越来越流行的视角,在我们继续探索非监督学习时也值得回顾。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论