昨日翻看朱世武老师的《金融计算与建模》幻灯片(来源,幻灯片“13随机模拟基础”),其中提到了中心极限定理(Central Limit Theorem,下文简称CLT)及其SAS模拟实现。由于我一直觉得我们看到的大多数对CLT的模拟都有共同的误导性,因此在此撰文讲述我的观点,希望能说清楚CLT的真实面目,让读者对它有更深刻的理解。
一、中心极限定理说了什么
从广义的角度来讲,CLT说的是一些随机变量之和(在n趋于无穷的时候)趋于正态分布,条件是这些随机变量之间相关性不要太严重,每个随机变量自身的方差相对来说不要太大。我们平时看到的都是CLT的最简单的形式:随机变量独立同分布,方差有限。实际上独立同分布不是必要的条件。要理解这段话,我们就得去思考一下Lindeberg条件或Liapounov条件的含义,以及非独立情况下的CLT。而CLT为什么偏偏选中了正态分布呢?这主要是泰勒展开的功劳(注1),加上特征函数作为“催化剂”,捣鼓半天,最后一看,特征函数的极限形式正是正态分布。本文不打算走到这样偏僻的数学角落,只是先介绍一下CLT的前世今生,当我们在统计理论上犯迷糊的时候,回溯到事情的最原始状态,往往能让头脑更清醒(注2)。
即使是最简单的CLT,我觉得几乎所有做模拟的人都走入了一个误区,就是把钟形密度曲线解释为正态分布。给一个非正态的总体分布,重复计算若干次样本均值,把密度以直方图或密度曲线的形式画出来,给观众们说,看:钟形曲线!群众们一看,哇,原本是左偏/右偏/水平的密度,现在真的变成了对称的钟形曲线。于是乎不得不信服CLT的魔力。
二、中心极限定理的模拟
我们缺的不是钟形曲线,而是样本均值的分布和正态分布差多少的指标。这一点在下面第3小节中再谈,先看几个常见的模拟例子。
1、对称的钟形曲线不代表正态分布
很多人喜欢用掷骰子的例子来讲中心极限定理,大意是将两次独立掷骰子的结果加起来,看这个和的分布。我犹记当年人大一位老师给我们上抽样就举了这个例子说明CLT的魔力:看,即使样本量为2,得到的分布也是正态分布!恰好昨天在朱老师的幻灯片中又看到这个例子,不禁感叹这样一个糟糕的例子竟然经久不衰。这个例子的骗局在哪儿呢?其实很简单:在于掷骰子得到的结果的“对称性”,换句话说,结果是1、2、3、4、5、6,这6个数字围绕其均值3.5左右对称,因此两次骰子的结果加起来也围绕7对称,再画个图,两边低,中间高,看似正态分布好像出来了。朱老师的SAS代码如下:
data a;
do x1=1 to 6;
do x2=1 to 6;
output;
end;
end; /*模拟掷骰子两次,生成36行数据*/
data a;
set a;
x=sum(x1,x2);
proc univariate data=a noprint;
var x;
histogram/normal (mu=est sigma=est);
run;
先跑题说一处细节:这段代码中的直方图不合适,因为我们知道结果x只可能是整数,而(SAS)直方图默认的分组也会以整数为边界,每个边界上的整数都被归到右边的条中去了,而这个所谓的直方图其实只是个条形图:展示每种结果的频数。所以这种情况下认为指定非整数的分组边界才能显示数据真实的分布。以下是R代码:
x = rowSums(expand.grid(1:6, 1:6))
hist(x, breaks = seq(min(x) - 0.5, max(x) + 0.5, 1), main = "")
 两次掷骰子得到的结果之和的分布
两次掷骰子得到的结果之和的分布
样本量为2的时候真的得到正态分布了么?CLT确实有它的神奇之处,但还没那么神奇。以上结果如我前文所说,仅仅是由于样本空间中的元素的对称性,所以得到了一副对称的图形,看起来像是正态分布,如果我们再用另外6个数字试验一下,马上就看穿这种迷惑了,我把最后一个数字换成15再看直方图:
d = c(1, 2, 3, 4, 5, 15)
x = rowSums(expand.grid(d, d))
hist(x, breaks = seq(min(x) - 0.5, max(x) + 0.5, 1), main = "")
 6个数字中2个样本之和的分布
6个数字中2个样本之和的分布
如何?“正态分布”哪里去了?客官是否能看清骰子中的中心极限定理谎言了?
2、直方图上添加正态密度曲线有误导性
在我还会用SPSS的年代(大约是SPSS 15.0),我就发现SPSS的一个荒唐之处,它的直方图有个选项,可以控制是否添加正态密度曲线。我们被“正态”毒害得多深,从这些软件设置就可以看出来。为什么只能加正态密度曲线,而不能加数据自身反映出来的核密度估计曲线?换句话说,数据的分布一定要是正态么?
我们看CLT的模拟,很多人也喜欢在直方图上加上正态分布密度曲线,这有一定道理:可以看直方图跟正态密度的差异有多大。然而,我们却很少见直方图上的核密度曲线(注3)。既然是要作比较,就拿最可比的去比,比如曲线对曲线,直方图对直方图,人眼本来就是不精确的测量工具,那么制图者就应该提供尽量准确而方便的参照系。
3、给出拟合好坏的指标
综上,我在两年多以前已经把这些CLT模拟的想法写成函数收录在R包animation中,参见函数clt.ani()。代码及输出如下:
if (!require(animation)) install.packages("animation")
library(animation)
ani.options(interval = 0.1, nmax = 100)
par(mar = c(4, 4, 1, 0.5))
clt.ani()
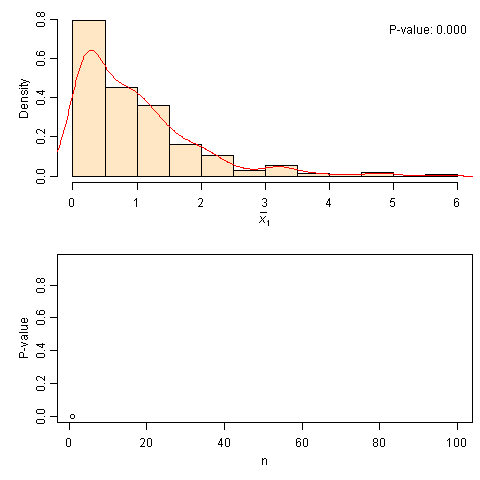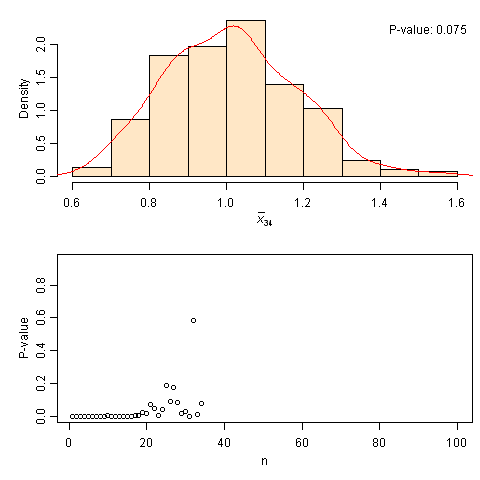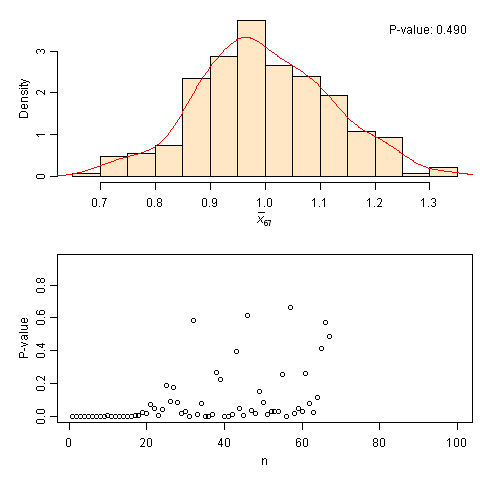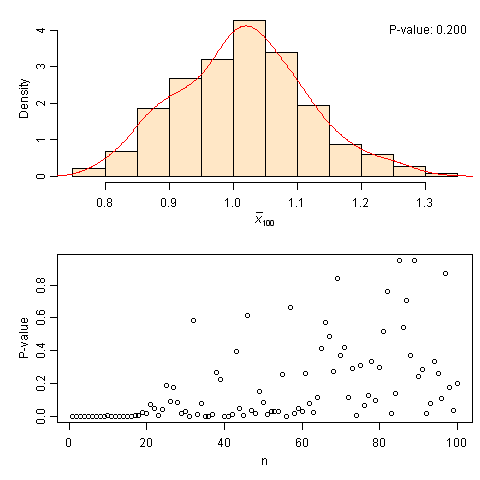 中心极限定理模拟:从指数分布到正态分布
中心极限定理模拟:从指数分布到正态分布
这个CLT模拟的过程很简单:给一个总体分布(默认为右偏的指数分布),在给定样本量n时不断重复抽样分别计算样本均值,一直这样计算obs个均值,并画出它们的直方图和相应的核密度估计曲线;然后随着n增大,看相应的样本均值分布如何。此外,我使用了Shapiro正态性检验来检验这些均值的正态性,并把P值取出来画在下半幅图中。这样我们就很清楚地知道,对于每一种样本量(n = 1, …, 100),我们的样本均值究竟离正态分布多远。此处P值就充当了一个拟合好坏的指标。可以看出,上面的动画中,当样本量n超过20之后,P值会普遍偏大,也就是样本均值的分布和正态分布比较接近(严格来说,是“不能拒绝正态分布”),但也不能保证样本量大就一定意味着正态分布,譬如上图中n=40的时候P值就很小。
三、小结
正态分布在统计中的地位如此之重要,以至于人们几乎认为正态是一种自然而然的分布,本文想说明的是,正态有它的自然性(参见注1),但我们不能逮着两边低中间高的东西都叫正态(参见小学课文《小蝌蚪找妈妈》);做模型或分析数据之前,先清空脑子里的这种“正态教义”,用事实说话。
另外,前面胡江堂挖了个大坑,大家跳进去争论了半天SAS和R的问题,我在这里也挖个小坑:就模拟而言,如果有SAS用户愿意研究一下,我想知道朱老师的SAS模拟代码是否有改进的余地。SAS自70年代创立,过了二十多年才引进“函数”这种杀人越货编程必备之工具,一直以来都是“宏”的天下,说它“恐龙”应该也不冤枉吧。朱老师幻灯片中的长篇SAS代码,如果用R改写,应该都不会超过三五行甚至一行(注4),而反过来可能就麻烦了,比如上面的动画(用SAS怎么写?),它用R之所以方便,是因为R大量的统计相关的函数可任意调用,而图形也很灵活,可以把P值动态写在图例的位置,也可以愿意把样本量n作为下标动态写在\(\bar{X}\)旁边。
脚注
注1:以我的浅见,统计学中绝大多数极限正态分布的来源都是泰勒展开,主要是因为泰勒展开中有一个平方项,这个东西和正态分布的密度函数(或特征函数)看起来形式相似,再加上一些对高次项的假设(使它们在极限中消去),正态分布也就来了。另一个典型例子是极大似然估计的渐近正态性:泰勒展开中一阶导数为零,剩下二阶像正态。此外,正态分布有个独特的特点,就是它的密度函数和特征函数长得很像,冥冥之中也主导了很多统计量的分布(这一点我还没太想清楚)。
注2:我很少见统计学家强调这种想法的重要性,仿佛大家都埋在公式堆里都推导得倍儿高兴。有两个例外:一个是Brian Ripley教授,我在看他的一份幻灯片Selecting amongst large classes of models的时候发现他竟然回顾了AIC的假设条件——这是我见过的唯一一个讲模型选择时会回到数学根源的人;另一个是Ripley的老搭档,Bill Venables,他在他那著名的手稿Exegeses on Linear Models中竟然从泰勒展开来说线性模型的来历,这也是我在所有我读过的线性模型相关的文章和书中看到的唯一一份从泰勒展开角度谈线性模型的材料。我个人并不喜欢数学,但我喜欢看思路。
注3:我的观点是,画直方图尽量加上核密度估计曲线,因为它能刻画数据在任意位置上的密度大小,而直方图的形状则完全受制于分组边界的位置。当然,核密度估计曲线也取决于核函数,但大多数情况下,核函数不会对曲线的形状有太大的影响。不过邱怡轩在前面“有边界区间上的核密度估计”一文中提到的问题很值得注意。
注4:伯努利随机变量之和的分布。SAS代码:
symbol;
goptions ftext= ctext= htext=;
%macro a(n);
data rv;
retain _seed_ 0;
do _i_ = 1 to &n;
binom1 = ranbin(_seed_,&n,0.8); /*ranbin函数返回以seed、n、0.8为参数的二项分布随机变量*/
output;
end;
drop _seed_ _i_;
run;
%mend;
%a(100);
proc univariate data=rv noprint;
var binom1;
histogram/normal( mu=est sigma=est);
inset normal ;
run;
R代码:
a = function(n) hist(rbinom(n, n, 0.8))
什么叫向量化编程?这就是R它爹S语言诞生的原因之一:统计学的编程不应该涉及到那么多繁琐的循环。
关于作者
谢益辉中国人民大学统计硕士,爱荷华州立大学统计学博士,R 包 knitr 的主要作者。现为 RStudio 软件工程师,曾负责 Shiny 包相关开发工作,后转入 R Markdown 相关扩展包的开发,包括 bookdown 和 blogdown。对统计计算、可视化、以及各类网页相关技术感兴趣,有志于对技术写作工具做减法工作,坚信人类浪费了太多时间在期刊论文、学位论文、书籍的排版上。平时主要活跃在 Github 上。个人主页在 https://yihui.org,思想偏激,流水账、意识流甚多,小人之心甚重,慎入。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论