很多事很多人在做也知道怎么做能做好,这是工程师思维;但只有知道为什么去做才能从更深层次的改造现有的方法或手段,这就是科学家思维了。现在的大学教育特别是理工科教育都过于强调职业精神,各专业之间都有很深的隔阂来凸显自己的价值。但追根溯源,所有知识都有个起源,或者是实际需求,或者仅仅就是好奇心,理清了来源再去想很多东西思路就会十分清晰,而不是淹没在一堆术语中。**《The Seven Pillars of Statistical Wisdom》**就是一本着力于讲清楚统计学出发点的书,作者是芝加哥大学统计系的 Stephen M. Stigler 教授。我个人的统计知识都是上网络公开课的“夜校”学的,但读起来也并不吃力,推荐科研人员特别是做数据分析的科研人员都读一下。如果你懒得读,我就二手解读下,不保真。

《The Seven Pillars of Statistical Wisdom》封面(图片来自网络)
支柱一:聚合
统计学毫无疑问是一门独立的学科,经常很多人搞混统计跟数学,其实数学在各个学科里都更多是以抽象工具的角色出现,统计学也并不例外。最原始的统计需求就是对客观世界的抽象,跟农业最相关的天文观察要求所有测量要准确,但问题每次测出来都会有差异,那么就需要一个方法来描述相似但不一样的测量值,这就是统计聚合思想的来源。科幻小说出现的具备照相机记忆的人是无法分析事物的,他们只能记住所有细节,而这个负担是非常重的,此时抽象的意义就很大了。现在比较火的大数据就好比这个人,细节丰富但需要有意识地抽象,不然就是一堆数字的堆砌。这里最常见的统计学术语就是众数、中位数还有均值,都是聚合抽象描述的体现。
其实这个思想提出时也是被批判的,因为显然聚合出来的东西例如平均人不是客观存在的,也就没法指导具体事物的描述。但本来聚合描述的就不是具体事物,它用总结替代完整描述,通过选择性舍弃一部分信息来获得更有价值的信息,这可以说是统计学的一个根基。
支柱二:信息测量
在这个支柱一上我们提到了信息,那么对应另一个支柱就是对信息的测量,因为我们要知道保留哪一些而舍弃哪一些。当我们构建一个统计量时,其实是丢掉了一些与目的无关的信息的。更有意思的是,对同一个事物的描述,即便测量的准确性上没有差别,后来的观察贡献的信息并不如早期多,信息量与观测数的平方根成正比而不是观测数(我严重怀疑这个说法借鉴了薛定谔的《生命是什么》)。举例来说,早期造币按批次称重,误差 r ,10 个一起称的误差并不是 10r,100个一起称也不是 100r,你称 10 个得到的误差与称 100 个得到的误差精度最多高一倍,也就是后面 90 个硬币提供的信息大概等同于前 10 个提供的信息,这个现象也是统计学里很常见的,基于此我们可以去搞采样及基于分布的理论而不至于担心丢失太多信息。
支柱三:似然度
另一个基础思想则是似然度,前面两个基础思想都是面向测量的,有了测量就可以进行比较。最通常的比较就是跟随机事件比,而有了随机事件就可以谈概率了。此时特定分布下概率就是似然度,看看某件事在大背景下出现的可能。p 值理论的根基就是似然度概率且最初的 p 值概念里就是仅仅去看零假设下的发生概率。1920 年 Fisher 提出,如果 A 代表科学目标,X 代表数据,那么定义似然度函数 L(A|X) 为出现 X 的 A 的概率密度函数,X 已知,找这个函数最大时的 A,一阶导数为0找到参数,二阶导数描述准确性,但这里面最大的问题在于样本数量很少时对于方差估计是有偏的,同时如果描述样本的维度高了这个问题会更加严重。
抛开这个,基于概率的推理本身就是统计学很特殊的世界观,简单说就是只要概率不为零,一切皆可能。休谟认为奇迹是违反自然法则而不能发生的,但 Price 用贝叶斯理论推导认为即使发生概率很小,多次实验后也会发生奇迹,在这里经验法则跟统计规律就出现了对立。传统世界观是决定论的、逻辑的,但统计世界观是概率的,不可知的或可更新的,值得注意的是,这种不可调和的差异也存在与量子力学与经典力学的世界观之间。很难说哪种是世界本来面目,只能说这是两种认知角度,可以矛盾地存在于同一个人身上。
支柱四:内部比较
有了面向背景目标的似然度,统计学可以解决外部比对问题,也就是跟预设分布去比较。然而,现实问题更多是数据内部的异质性所要求的内部比较,很多耳熟能详的统计方法例如 t 检验、方差分析、Bootstrap 等都是用来解决内部比较问题的。1908年, Gosset 用 Cushny-Peebles 数据展示单样本t检验,他考虑了样本方差在样本数较少且总体方差未知时如何估计,引入了自由度与样本方差,得到一个近似正态分布的t分布,这篇论文印错了数、分类也错了、引用年份也错了,但最后结果还可以有历史意义的。但其实这篇论文出版后很长时间无人问津,包括 Gosset 本人都忽略了,直到 Fisher 在 1912 年从剑桥毕业后发现了这篇论文,他写信给 Gosset 想讨论证明问题,但 Gosset 没看懂,后来又转给 Pearson 但也没看懂。最后 Fisher 自己撸袖子证明了并进一步提出双样本 t 检验,他结合相关系数与方差分析写在了 1925 年的教科书 《Statistical Methods for Research Workers》 中,到这里这个相对通用的内部比较方法才开始真正流行。再往后 Tukey 提出了 jackknife ,Efron 提出了 Bootstrap,都是从样本内部进行比较来估计差异变化。值得注意的是数据量越大,内部比较中出现偶然相关的可能性就越大,而时间序列数据也有自相关问题,这是很容易忽视的差异变化来源。

故事涉及的统计学家(图片除 Efron 外来自维基百科,Efron 照片来自其斯坦福个人主页)
支柱五:回归
回归思想应该是统计学作为世界观最直接的体现,一般人看世界是发展的或静止的或规律决定的,但统计学家看世界是自带回归视角的,也就是说,凡事都会回归到本来的样子,规律性是松弛有度的。
用进化论来说,最初其理论体系是不完整的,里面假设了同一个亲代会产生不同的子代,如果不断产生,这个变异累计会无穷大,出现怪物,实际代际间差异并不大。这里的矛盾是等比法则(a/b = c/d)例如身高体重比如果稳定可以知三得一,这样子代的高身高一定意味着高体重,但现实数据并非符合这个强规则。
这个问题最早被高尔顿钉板所捕捉:如果关注极端小部分 会发现其主要来源是不极端的部分;相反不极端的部分也会有来自极端部分的回归。然后研究身高时,高尔顿发现孩子身高会有向父辈身高均值回归的现象:每个人的身高都有固定部分跟变动部分,固定部分是都一样的,这样代际变化可以用亲代子代的不完全相关来解释,达尔文的自然选择就可以构建在遗传学理论上了,至此人口平衡与代际变异就可以有统计模型来和谐相处了。否则不论是强相关还是不相关都不能解释现实数据,回归思想可以说是统计学的中庸之道。
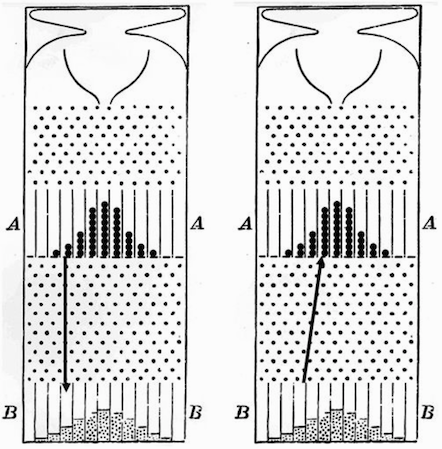
高尔顿钉版中的回归现象:左图表示上槽中弹珠在经过钉版后的平均位置,可以看到回归均值;右图表示下槽较极端位置弹珠的平均初始位置,可以看出来自不极端的部分(图片来自本书,原始文献来自 Galton 1889年发表的论文)
这个将效应区分为固定跟临时两部分的思想也构成了经济学里消费函数的根基,人们消费固定部分是收入而不是短期刺激,因而政府短期加大开支并不能刺激消费,这个指导思想帮助弗里德曼拿了诺奖。
多元问题在多元统计方法之前都是用几何学跟数据分析混合求解,所以最多就是两元平面分析,Galton 提出相关系数后,Pearson 等人发扬光大为多元分析。而贝叶斯统计则先假设参数分布与这个参数下出现数据的似然度,然后去求出现这个数据的参数,这种推断比较依赖假设,初始值变了就都变了。现代统计学的另一个新兴分支因果分析就是基于强假设进行推断。
支柱六:实验设计
前面讲的统计学是收敛的,观察的,但当发展到实验科学年代,统计学就要去解决刻意观察获得规律的方法。这里面随机化是一个核心观念,用来确保除了你关心的变量,其余的都能随机或符合某个分布。1874在《科学原则》这本书里首次提到了控制变量法,一次测一个。但在统计学大放异彩的20世纪,Fisher 认为一次回答一个问题是错的,因为自然问题从来都是复杂的不能只关注一个,提出了加性模型。这里统计学要为复杂现象提供合理的设计工具,时至今日,在数据概念满天飞的时代数据收集似乎不是问题,很多人就会说更重要的是提出问题。这倒没错,但如果没有统计学实验设计思维的加持,很多问题是无法对应实际数据的,我想 A/B 测试就是一个很好的例证,如果设计不当或有偏,拿到的现象就会产生误导。但反过来说,如果想让统计学真正进入其他学科,就要去理解实际问题而不仅仅是套用新的模型。当然在深度学习满天飞的今天似乎理解模型本身已经不如解决实际问题重要了,这里面有还原论与系统论两种科学思想的对立。但就我个人经验而言,实验类基础学科学术圈对黑箱或灰箱模型有天然的抗拒,调查类基础学科及工程上则对这类模型更友好些。
支柱七:残差
这是我个人非常欣赏的一个统计要素,本质上科学就是通过解释剩余现象进步,而当今其实理论体系里留给重大发现的空间是有限的,所有人都在力图精进 1%,不过都是在 80%-90% 的基础上的,也就是大家伙都在当前的噪音里探索未知信号的模式。具体到统计模型就是对模型解释不了的部分与模型诊断的思想,有了这个部分统计学就有了不断发展的动力与自我审视的原则。
逻辑上看这本书其实有点内容上的前后重叠,但思想上却是很有启发的,如果一个人熟悉统计学的世界观,那么他可能会更好的与这个世界相处:既不会被教条的规则所折磨,也不会被充沛的情感所奴役。科研人员其实就经常盘旋在理性与感性之间,统计学可以很好的把感性观察或假设转化为理性规律,为科学进步保驾护航。统计学世界观其实是有点人文关怀在里面的,不论是把个体包裹在整体之中、为奇迹赋值、为发展提供理论空间还是回归的中庸之道,当然这几点也可能有完全不同的解读方法。
关于作者
于淼中科院生态环境研究中心博士,就职于美国杰克逊实验室,博客 https://yufree.cn |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论