本文引用的所有信息均为公开信息,仅代表作者本人观点,与就职单位无关。
1 本文概览
空间地理可视化的内容非常丰富,涉及空间坐标投影、操作空间数据、选择图形种类、选择绘图工具等。就图形种类而言,对标鼎鼎大名的收费 BI(Business Intelligence) 工具Tableau,至少包含最常见的面量图、比例符号地图、点分布图、流线图、蜘蛛图(飞线图)、热图。其中的「面量图」通常又叫专题地图、地区分布图、统计地图,英文一般为Choropleth map,典型样例是基于统计年鉴的各类专题数据的地理可视化,国家地理信息公共服务平台提供了专题图层服务,可以快速地查看各个统计指标。在美国和日本的国家统计局官网,地区分布图用于展示各类指标[1]。衡量一个部门、一个业务、一个公司、一个行业,乃至一个国家都有一套金字塔式的指标体系,而国家每年发布的统计年鉴就包含一套衡量经济和社会发展情况的指标体系,涵盖人口、土地、生产、消费等等专题,省、市、区县以及自治区、州、县等各级地方统计局每年也会发布一份地方统计年鉴。
接下来,本文分四个部分展开介绍地区分布图,分别是单变量情形、多变量情形、本文小结和未来展望。
单变量情形中以 latticeExtra 包[2]内置的数据集 USCancerRates 为例,以地区分布图形式展示美国 1999-2003 年度各郡的年平均癌症死亡率,此处专题的含义是「人口死亡率」,显而易见,癌症死亡率只是一方面,还有流感死亡率等,癌症可以分类型,如乳腺癌、子宫癌等,人又可以分属性,如性别、年龄、种族等等。在数据操作、指标计算和分面绘图等方面从零开始介绍绘制地区分布图的过程,包括基础数据操作以及六个绘图工具 maps 包[3]、latticeExtra 包、ggplot2 包[4]、tmap 包[5]、sf 包[6]和 mapsf 包[7],阐述数据指标「年平均癌症死亡率」的实际含义、指标口径和计算过程,从易到难,层层深入,以期达到出版级的水准,探索出最佳实践。
多变量情形中以美国人口调查局发布的调查数据为基础,分析北卡罗来纳州各郡社区普查级的家庭年收入与白人占比的空间相关性。先以单变量的地区分布图描述各个普查区域里家庭年收入的空间分布,接着和二元变量的地区分布图形成对比,展示相关性的空间分布。
本文小结部分给出了 7 种不同绘图方案间的关系和一些绘图经验,希望帮助读者加深理解和学习。
未来展望部分从应用场景和绘图技术方面继续提供一些示例,供读者继续探索。
2 单变量情形
2.1 美国各郡的年平均癌症死亡率分布
下面以 latticeExtra 包[2]内置的 USCancerRates 数据集为例介绍分面,同时展示多个观测指标的空间分布。USCancerRates 数据集来自美国国家癌症研究所(National Cancer Institute,简称 NCI)。根据1999-2003年的5年数据,分男女统计癌症年平均死亡率(单位十万分之一),这其中的癌症数是所有癌症种类之和。癌症死亡率根据2000年美国标准人口年龄分组调整,分母人口数量由 NCI 根据普查的人口数调整,即将各年各个年龄段的普查人口数按照 2000 年的美国标准人口年龄分组换算。因latticeExtra 包没有提供数据集的加工过程,笔者结合 NCI 网站信息,对此数据指标的调整过程略加说明,这里面其实隐含很多的道理。
人口数每年都会变的,为使各年数据指标可比,人口划分就保持一致,表2.1 展示 1940-2000 年各个年龄段(共19个年龄组)的标准人口数,各个年龄段的普查人口数换算成年龄调整的标准人口数,换算公式为:
\[ \text{某年龄段标准人口数} = \text{某年龄段普查人口数} / \text{总普查人口数} * 1000000. \]
以 2000 年的 10-14 岁年龄段标准人口数为例,即:
\[ 73032 = 20056779 / 274633642 * 1000000. \]
| Age | 2000 | 2000 (Census) | 1990 | 1980 | 1970 | 1960 | 1950 | 1940 |
|---|---|---|---|---|---|---|---|---|
| 00 | 13,818 | 3,794,901 | 12,936 | 15,598 | 17,151 | 22,930 | 20,882 | 15,343 |
| 01-04 | 55,317 | 15,191,619 | 60,863 | 56,565 | 67,265 | 90,390 | 86,376 | 64,718 |
| 05-09 | 72,533 | 19,919,840 | 72,772 | 73,716 | 98,204 | 104,235 | 87,591 | 81,147 |
| 10-14 | 73,032 | 20,056,779 | 68,812 | 80,523 | 102,304 | 93,538 | 73,785 | 89,208 |
| 15-19 | 72,169 | 19,819,518 | 71,384 | 93,439 | 93,845 | 73,717 | 70,450 | 93,670 |
| 20-24 | 66,478 | 18,257,225 | 76,476 | 94,103 | 80,561 | 60,231 | 76,191 | 88,007 |
| 25-29 | 64,529 | 17,722,067 | 85,694 | 86,168 | 66,320 | 60,612 | 81,237 | 84,277 |
| 30-34 | 71,044 | 19,511,370 | 87,905 | 77,516 | 56,249 | 66,635 | 76,425 | 77,789 |
| 35-39 | 80,762 | 22,179,956 | 80,267 | 61,644 | 54,656 | 69,601 | 74,629 | 72,495 |
| 40-44 | 81,851 | 22,479,229 | 70,829 | 51,510 | 58,958 | 64,689 | 67,712 | 66,742 |
| 45-49 | 72,118 | 19,805,793 | 55,778 | 48,951 | 59,622 | 60,670 | 60,190 | 62,697 |
| 50-54 | 62,716 | 17,224,359 | 45,638 | 51,689 | 54,643 | 53,568 | 54,893 | 55,114 |
| 55-59 | 48,454 | 13,307,234 | 42,345 | 51,271 | 49,077 | 47,009 | 48,011 | 44,383 |
| 60-64 | 38,793 | 10,654,272 | 42,685 | 44,528 | 42,403 | 39,830 | 40,210 | 35,911 |
| 65-69 | 34,264 | 9,409,940 | 40,657 | 38,767 | 34,406 | 34,897 | 33,199 | 28,911 |
| 70-74 | 31,773 | 8,725,574 | 32,145 | 30,008 | 26,789 | 26,427 | 22,641 | 19,515 |
| 75-79 | 26,999 | 7,414,559 | 24,612 | 21,160 | 18,871 | 17,028 | 14,283 | 11,422 |
| 80-84 | 17,842 | 4,900,234 | 15,817 | 12,956 | 11,241 | 8,811 | 7,467 | 5,881 |
| 85+ | 15,508 | 4,259,173 | 12,385 | 9,888 | 7,435 | 5,182 | 3,828 | 2,770 |
| Total | 1,000,000 | 274,633,642 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 |
年龄调整的比率(Age-adjusted Rates)的定义详见NCI 网站,它是一个根据年龄调整的加权平均数,权重根据年龄段人口在标准人口中的比例来定,一个包含年龄 \(x\) 到年龄 \(y\) 的分组,其年龄调整的比率计算公式如下:
\[ aarate_{x-y} = \sum_{i=x}^{y}\Big[ \big( \frac{count_i}{pop_i} \big) \times \big( \frac{stdmil_i}{\sum_{j=x}^{y} stdmil_j} \big) \times 100000 \Big] \]
一个具体的例子可见网站,篇幅所限,此处仅以2000年举例,一个年龄段 0-0 死亡人数 29(可看作婴儿死亡人数),总人数 139879,则年龄调整的死亡率:
\[ aarate_{0-0} = \frac{29}{139879}*\frac{3794901}{274633642}*100000 = 0.2864 \]
读者可能有疑惑,一系列复杂的调整是为什么?指标稳定性和可比性。稳定不是代表不变,稳定是不轻易受干扰。从各社区、各郡、各州乃至国家,从下往上聚合数据的时候,分年龄、种族、性别等下钻/上卷的时候,有的郡总人口可能相对很少,死亡人数也很少。可比性是指组与组间可比,且随时间变化依然可比,刻画因癌症死亡的相对风险。
# 加载死亡率数据
data(USCancerRates, package = "latticeExtra")
# 查看 Alabama 的 Pickens County 的数据
subset(x = USCancerRates, subset = state == "Alabama" & county == "Pickens County")
# rate.male LCL95.male UCL95.male rate.female LCL95.female
# alabama,pickens 363.7 311.1 423.2 151 123.6
# UCL95.female state county
# alabama,pickens 183.6 Alabama Pickens County以 Alabama 的 Pickens County 为例,1999-2003年平均年龄调整的男性癌症死亡率为 363.7(单位:十万分之一),在 95% 置信水平下,置信限为 \([311.1, 423.2]\)。根据最新的五年数据显示 2014-2018 年男性癌症死亡率为 479.8,95% 置信水平下的置信区间为 \([425.7, 539.3]\)。简单验证一下,就会发现有意思的现象,置信区间不是关于观测的癌症死亡率对称,且离置信区间中心尚有距离, \(\frac{311.1 + 423.2}{2} = 367.1 \neq 363.7\)。一般来说,100000 人中有 363.7 人因癌症死亡,死亡人数较多(比如大于100)的情况下,二项分布可用正态分布逼近,置信区间上下限应该分别为:
qnorm(p = 1 - 0.05 / 2)
# [1] 1.96
# 置信下限
363.7 - 1.96 * sqrt(363.7 / 100000 * (1 - 363.7 / 100000) / 100000) * 100000
# [1] 326.4
# 置信上限
363.7 + 1.96 * sqrt(363.7 / 100000 * (1 - 363.7 / 100000) / 100000) * 100000
# [1] 401而美国国家癌症研究所给的置信带更宽,更保守一些,显然这里面的算法没这么简单。以阿拉巴马州为例,将所有的郡死亡率及其置信区间绘制出来,如图2.1所示,整体来说,偏离置信区间中心都很小。
图 2.1: 1999-2003 年美国阿拉巴马州各个郡的年平均癌症死亡率
不难看出,女性癌症死亡率整体上低于男性,且各个地区的死亡率有明显差异。NCI 网站仅对置信区间的统计意义给予解释,这跟统计学课本上没有太多差别,没有提供具体的计算过程。可以推断的是必然使用了泊松、伽马一类的偏态分布来刻画死亡人数的分布,疑问尚未解开,欢迎大家讨论。
癌症死亡率相关数据仅可用于统计报告和分析,不可用于其他目的,请遵守相关法律规定。
2.1.1 maps
分析和展示地理信息数据是一项常规任务,约 30 年前,Richard A. Becker 等为 S 语言引入地理可视化,特别是本文介绍的地区分布图,以及简单的区域面积和区域中心的计算能力[3, 8],而后到了 2003年,Ray Brownrigg、Thomas P Minka 和 Alex Deckmyn 等将其引入 R 语言社区并持续维护至今[9]。除了最基础的 maps 包,还有坐标投影 mapproj 包[10],以及提供更多地图数据的 mapdata 包[11]。那个时候,因缺乏一些基础工具,在地图数据获取、空间数据操作和可视化方面都不太容易,仅用这些能做到下图2.2已属不易。
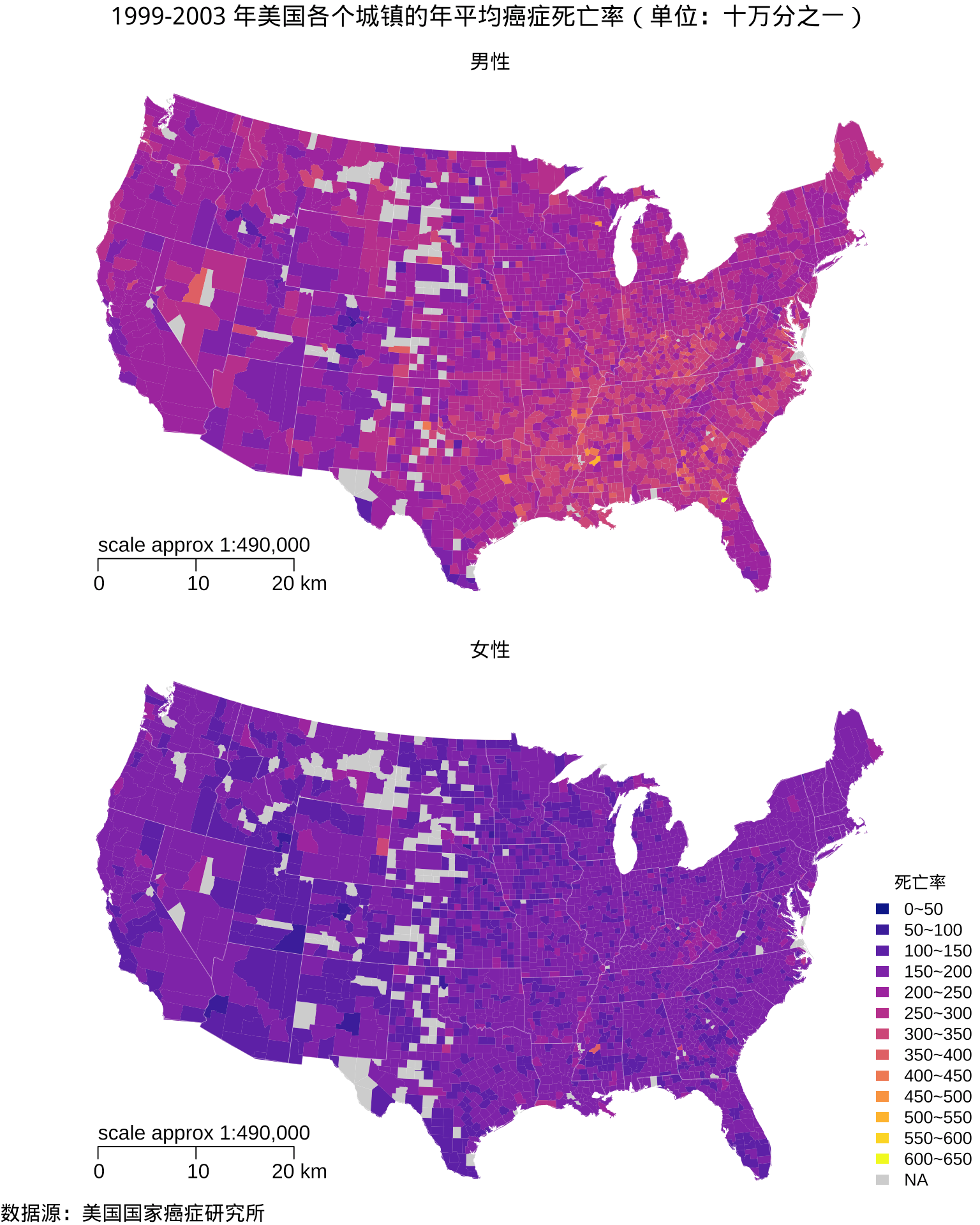
图 2.2: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
# 加载数据
data(USCancerRates, package = "latticeExtra")
library(maps)
# 郡地图数据
us_county <- map("county", plot = FALSE, fill = TRUE, projection = "polyconic")
# 奈何 maps 内置的地图数据不全,仅保留部分观察数据
USCancerRates2 <- subset(
x = USCancerRates,
subset = rownames(USCancerRates) %in% us_county$names
)
# 调色板
colors <- viridisLite::plasma(13)
# 图例文本
leg.txt <- mapply(paste, 50*0:12, 50*1:13, collapse = " ", sep = "~")
# 癌症死亡率划分区间
USCancerRates2$colorBuckets_male <- as.numeric(cut(USCancerRates2$rate.male, 50*0:13))
# 根据城镇名称给地图上每个区域的癌症死亡率匹配颜色
colorsmatched_male <- USCancerRates2$colorBuckets_male[match(
us_county$names, rownames(USCancerRates2)
)]
# 对女性癌症死亡率类似操作
USCancerRates2$colorBuckets_female <- as.numeric(cut(USCancerRates2$rate.female, 50*0:13))
colorsmatched_female <- USCancerRates2$colorBuckets_female[match(
us_county$names, rownames(USCancerRates2)
)]
# 绘图
par(mar = c(0, 0, 3, 0), mfrow = c(2, 1))
# 添加地图背景
map("county",
col = "grey80", fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic"
)
# 绘制区县地图
map("county",
col = colors[colorsmatched_male], fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic", add = TRUE
)
# 添加州边界线
map("state",
col = "white", fill = FALSE, add = TRUE,
lty = 1, lwd = 0.2, projection = "polyconic"
)
map.scale()
# 添加图标题
title("1999-2003 年美国各个郡的年平均癌症死亡率(单位:十万分之一)", line = 2)
mtext(text = "男性", side = 3, adj = 0.5)
par(mar = c(1, 0, 2, 0))
map("county",
col = "grey80", fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic"
)
map("county",
col = colors[colorsmatched_female], fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic", add = TRUE
)
# 添加州边界线
map("state",
col = "white", fill = FALSE, add = TRUE,
lty = 1, lwd = 0.2, projection = "polyconic"
)
map.scale()
mtext(text = "女性", side = 3, adj = 0.5)
mtext(text = "数据源:美国国家癌症研究所", side = 1, adj = 0)
# 添加图例
legend("bottomright",
legend = c(leg.txt, "NA"), title = "死亡率", box.col = NA, border = NA,
horiz = FALSE, fill = c(colors, "grey80"), cex = 0.85, xjust = 0.5
)maps 包[3]内置的美国郡级地图数据欠缺阿拉斯加、夏威夷和波多黎各。数据集 USCancerRates 没有夏威夷、波多黎各各个郡的数据,阿拉斯加的部分郡有数据,如图2.2所示,不少郡没有收集到癌症死亡率数据,以灰色表示。值得一提的是,关于死亡率分级,不同的分法会带给人不同的印象甚至是错觉,此处是可以有操作空间的,特定的死亡率分割方式可以让男女死亡率的空间分布看起来差异不大或很大[12],详细介绍见 Marynia Kolak 和 Susan Paykin 在 2021 R/Medicine 大会上的视频和网页材料。
在数据操作方面,麻烦的是建立数据指标和各个地理区域的映射,上面反复用到函数 match(),Base R 有很多这样短小精悍的函数。下面简单介绍一下以助理解,函数 match() 返回一个向量,向量的长度与参数 x 一致,向量的元素是整型的,表示参数 x 中的元素出现在参数 table 中的位置,下面是三个小示例:
match(x = c("A", "B"), table = c("A"))
# [1] 1 NA
match(x = c("A", "B"), table = c("C", "A"))
# [1] 2 NA
match(x = c("A", "B"), table = c("C", "A", "D"))
# [1] 2 NA另外,maps 包内置的地图数据制作起来比较复杂,也很长时间没有更新了,笔者不推荐读者再从零开始构建 map 数据对象。sp 包[13]发布后,maps 包支持将 Spatial 数据对象转为 map 数据对象,这相当于引入了 sp 包及其生态在空间数据获取和数据操作方面的能力[14]。目前,美国国家人口统计局已提供了历年的州、郡、普查级多个比例尺的行政区划地图数据,配合 sf 包[6],可以很好地解决地理可视化的背景底图问题。一些以前看起来很难的问题,随着时间变迁,技术革新,已经解决了。
2.1.2 latticeExtra
maps 包是基于 Base R 绘图系统的,以线和多边形为基础,辅以颜色填充,还没有任何分层绘图的概念,Deepayan Sarkar 将其引入新的 Trellis(栅格)图形系统,这就有了 latticeExtra 包 [2],它是以 lattice 包[15]为基础的,特别适合多元数据可视化,不管数据是「宽格式」还是「长格式」都能轻松应对,既保留了 Base R 那种精细操作图形元素的能力,也引入图层面板的概念。如图2.3,在代码形式上将所有的操作都集于一身,没有严格的分层绘图,保留更大的灵活性的代价是提升了复杂性。绘图主要步骤如下:
- 准备数据:准备想要展示的数据指标
x,指标所在的数据集data,指标所描述的地理区域map,同时传递给函数mapplot(x, data, map, ...)完成图形主体部分。 - 添加配色:了解死亡率的分布情况,设置合适的分段,选择合适的调色板。
- 添加边界:函数
mapplot(x, data, map, panel, ...)中的参数panel需要一个函数作为参数值,修改默认的面板函数panel = panel.mapplot,添加各郡的边界线,再调函数latticeExtra::layer叠加各州的边界线,设置颜色深浅和边界线的粗线形成层次。 - 添加标题:添加横轴、纵轴、图例、分面标题,图形副标题,适当调整位置。
- 最后调整布局、刻度等细节。除了步骤1必须先做,后续步骤没有严格的顺序,图形中各部分是相对独立的,若遇覆盖情况则需注意顺序。
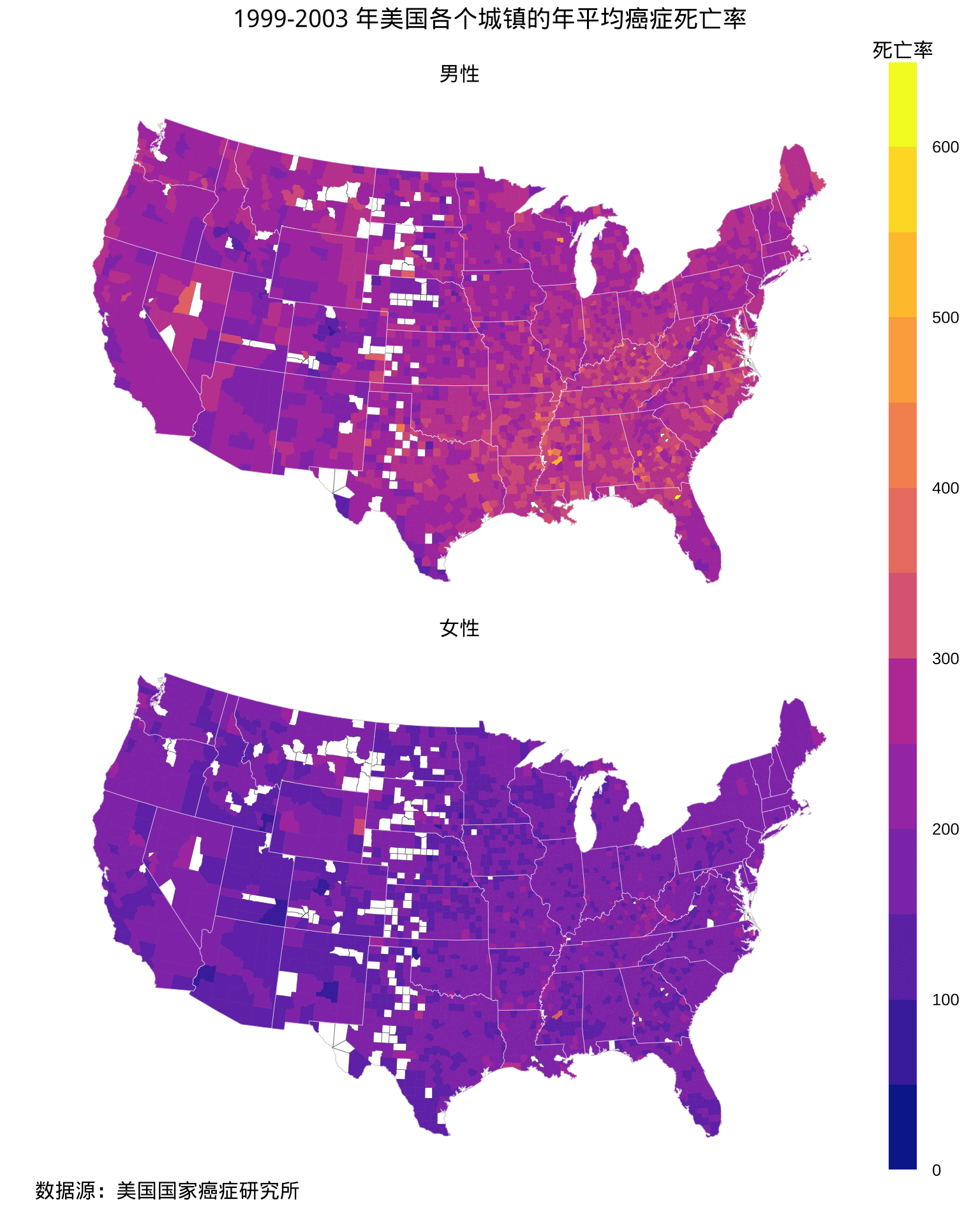
图 2.3: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
# 美国州边界数据
us_state <- map("state", plot = FALSE, fill = TRUE, projection = "polyconic")
library(lattice)
# 绘图
latticeExtra::mapplot(rownames(USCancerRates) ~ rate.female + rate.male,
# 观测数据
data = USCancerRates,
# 修改默认的面板函数
panel = function(x, y, map, ...) {
# 对未收集到癌症死亡率数据的郡,添加郡边界线
panel.lines(
x = us_county$x, y = us_county$y,
lty = 1, lwd = 0.2, col = "black"
)
latticeExtra::panel.mapplot(x, y, map, ...)
},
# 郡地图数据为背景
map = us_county,
# 填充地图用的调色板
colramp = viridisLite::plasma,
# 覆盖郡边界线
border = NA,
# 多图布局 2 行 1 列
layout = c(1, 2),
# 死亡率分桶数
# cuts = 14, # 指定 breaks 后就不需要 cuts
# 死亡率数据分割点
breaks = 50 * 0:13,
# 仅展示地图数据中包含的郡死亡率数据
subset = rownames(USCancerRates) %in% us_county$names,
# 取消坐标轴刻度
scales = list(draw = F),
# 修改分面展示文本
strip = strip.custom(factor.levels = c("女性", "男性")),
# 去掉横轴标签
xlab = "",
# 添加图例标题
legend = list(top = list(
fun = grid::textGrob("死亡率", y = 0.1, x = 1.03)
)),
# 常规图形参数列表 trellis.par.get('par.sub.text')
par.settings = list(
# 副标题放在左下角
par.sub.text = list(
font = 2,
just = "left",
x = grid::unit(5, "mm"),
y = grid::unit(5, "mm")
),
# 分面边界和背景色
strip.border = list(col = "white"),
strip.background = list(col = "white"),
# 轴线设置白色以隐藏
axis.line = list(col = "white")
),
# 副标题
sub = "数据源:美国国家癌症研究所",
# 主标题
main = "1999-2003 年美国各个郡的年平均癌症死亡率"
) +
# 添加州边界
latticeExtra::layer(panel.lines(
x = us_state$x, y = us_state$y,
lty = 1, lwd = 0.2, col = "white"
))用 lattice 包绘图往往可以一个函数搞定,参数非常多,都放在一起,这和 Base R 的绘图函数类似,也同时提供全局图形参数控制,但似乎更加复杂。下面谈几个细节:
只需传给参数
colramp一个生成颜色值向量的函数即可更改调色板,比如 R 内置的hcl.colors()或terrain.colors()等,为保持全文配色风格一致,图中配色采用 viridisLite 包提供的 plasma 调色板。参考 Markus Gesmann 在 2015 年写的一篇文章[16],设置 Lattice 图形参数
par.settings对图中的标题做了细致的调节,比如副标题的文本par.sub.text所有可调整的细节有:trellis.par.get("par.sub.text") # $alpha # [1] 1 # # $cex # [1] 1 # # $col # [1] "#000000" # # $font # [1] 2 # # $lineheight # [1] 1想必读者已看出其规律,以 R 语言的列表结构来传递各个层级的图形参数值。
参考 SO 论坛帖子设置参数
strip自定义了分面子图的标题文本,再在par.settings里对背景strip.background和边界strip.border微调,而类似的设置在 ggplot2 包的主题函数theme()里也有,在 R 控制台执行formalArgs(ggplot2::theme)可获得主题函数的参数列表。读者下一个疑惑可能是如何知道所有的图形控制参数,以及控制的精细程度,Deepayan Sarkar 在书里以图2.4归纳了,纵轴是图形参数,横轴是参数值名称列表[15],按图索骥一定有所帮助。
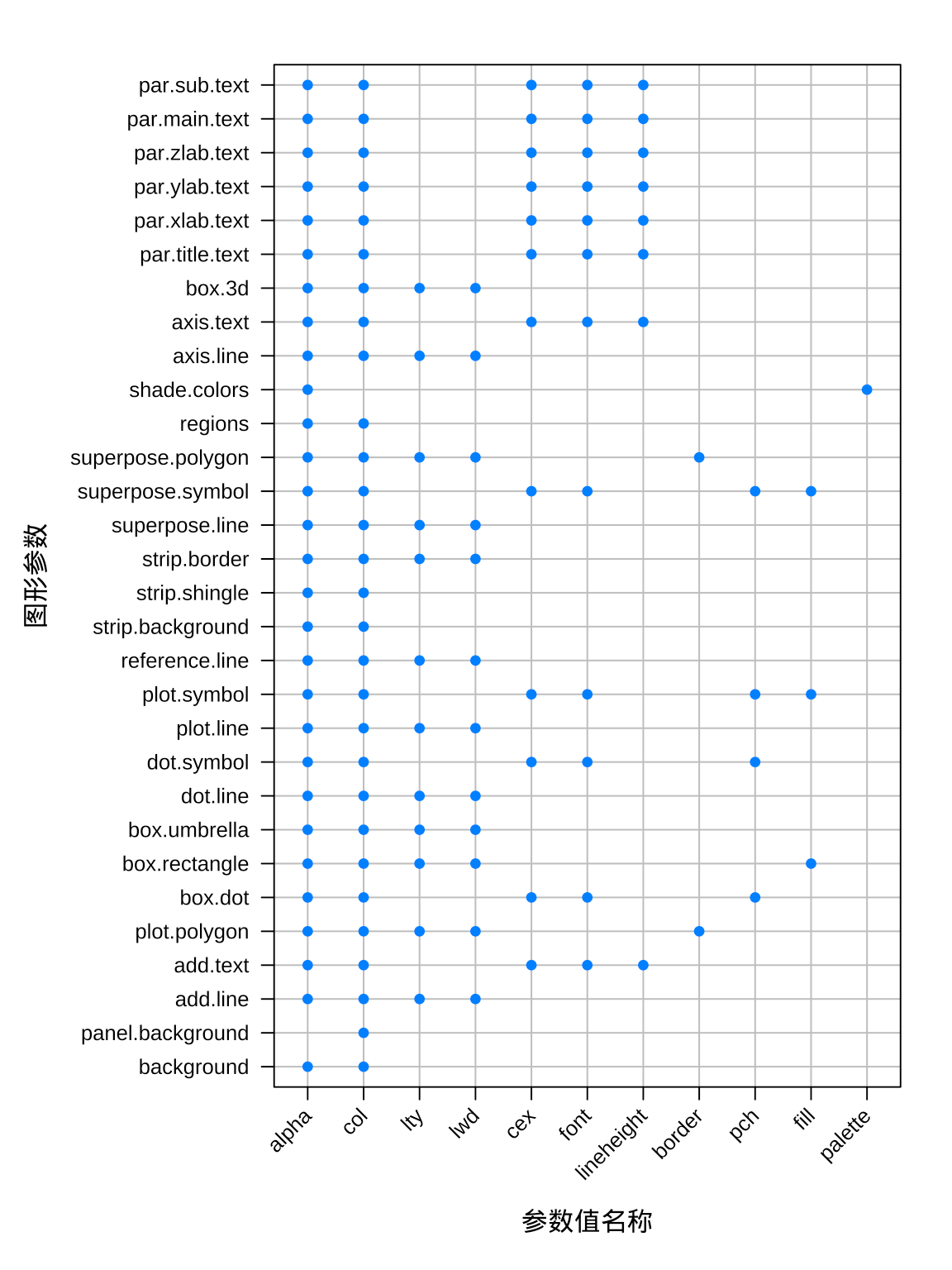
图 2.4: lattice 包常用图形参数一览
参数控制的效果预览如图 2.5 所示,不难看出,lattice 包[15]可以提供精细化的图形调整,是一个非常成熟的绘图工具。
图 2.5: 图形控制参数
如前所述,lattice 和 ggplot2 同出一脉,既然 ggplot2 有图层的概念,lattice 自然也有,除了 提供丰富的内置图层(约100个,读者可在控制台运行
apropos('panel')查看当前环境下可用的图层),也支持用户自定义图层,图2.6 展示叠加图层panel.superpose的效果,传递自定义的符号给pch参数,实际上修改了默认图形参数"superpose.symbol"。p1 <- xyplot(Sepal.Length ~ Sepal.Width, data = iris, groups = Species) p2 <- xyplot(Sepal.Length ~ Sepal.Width, data = iris, groups = Species, pch = c("L", "M", "N"), panel = panel.superpose ) print(p1, split = c(1, 1, 2, 1), more = TRUE) print(p2, split = c(2, 1, 2, 1), more = FALSE)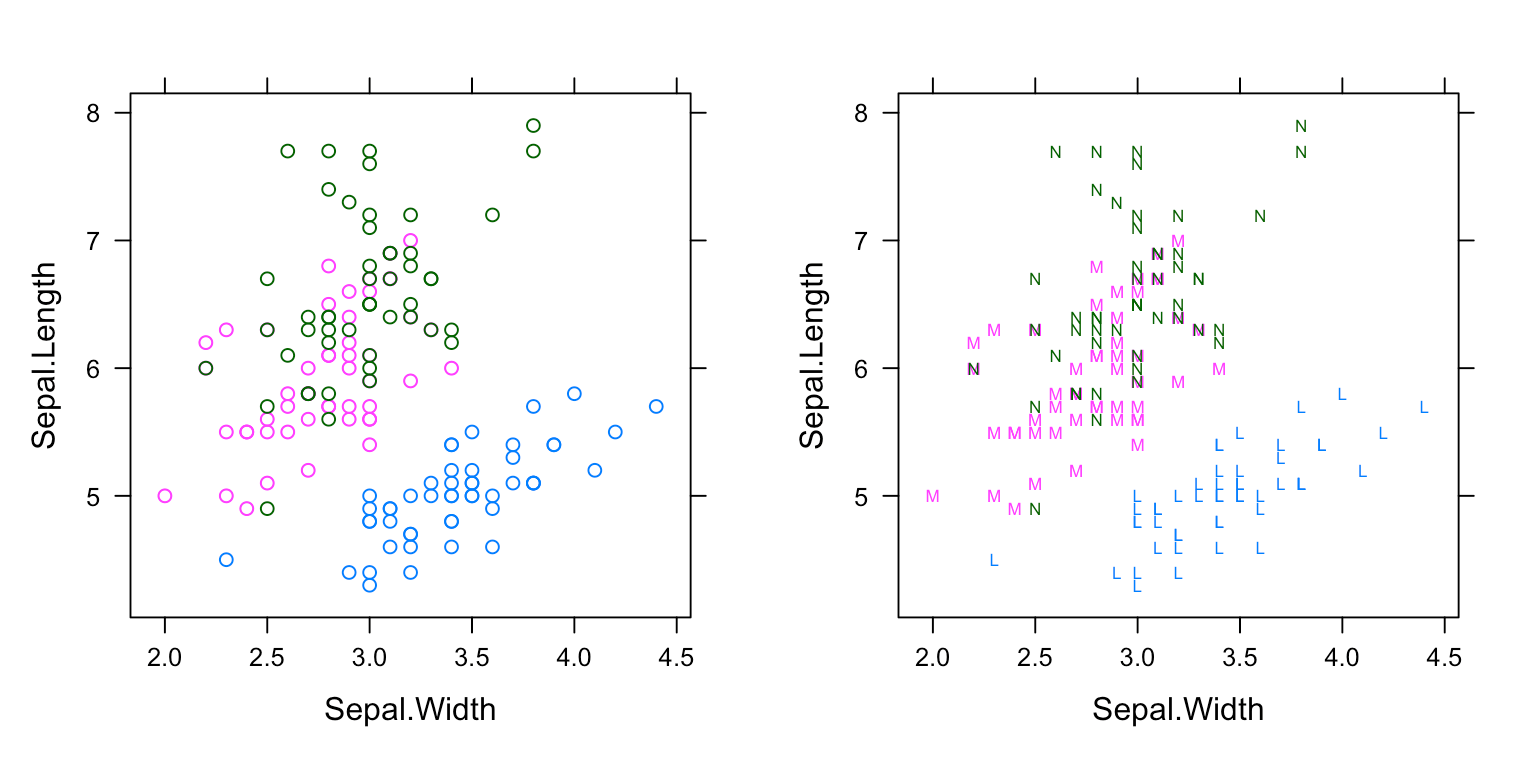
图 2.6: panel 叠加图层:左图默认散点图层,右图符号图层
此外,latticeExtra 扩展了图层功能,特别是
layer()函数,可在主体绘图函数之后直接叠加新图层。如上图2.3,在latticeExtra::mapplot()完成主体绘图工作后,添加美国各州边界线,有助于识别郡位置。大家应该都有这样一种感觉,将一张只有中国国家边界的地图放在面前,你不一定能清晰地指出每一个省份的位置,但只要画上各个省的边界,你肯定能指出更多的省份位置,类似地,从省到市、乃至区县,边界给了我们很好的参照。
2.1.3 ggplot2
考虑到 maps 包内置的地图数据的缺陷,ggplot2 包的流行度,下面采用 ggplot2 包绘制分面地区分布图,相比于 latticeExtra 包,ggplot2 包更适合「长格式」的数据,因此,需要先重塑 USCancerRates 数据集,将郡死亡率数据和郡地理边界数据配对,根据死亡率的分布设置合适分段,最后恢复地图数据的原始顺序。数据操作过程中有两点强调:
数据重塑:USCancerRates 数据集除了 state 和 county 列,剩余列是由三个原子指标按性别维度衍生出来的,分别是癌症死亡率及其置信区间的上、下限值。在「宽格式」转「长格式」过程中,要注意转化前后各个列名的对应关系。
数据关联:先将地图数据放左边,观测数据放右边,以 LEFT JOIN (左关联) 的方式关联起来,接着将连续性的死亡率数据分段,最后调用绘图函数绘制地区分布图。
# 宽格式转长格式
us_cancer_rates <- reshape(
data = USCancerRates,
# 需要转行的列
varying = c(
"LCL95.male", "rate.male", "UCL95.male",
"LCL95.female", "rate.female", "UCL95.female"
),
times = c("男性", "女性"), # 构成新列 sex 的列值
v.names = c("LCL95", "rate", "UCL95"), # 列转行 列值构成的新列,指定名称
timevar = "sex", # 列转行 列名构成的新列,指定名称
idvar = c("state", "county"), # 可识别郡的 ID
# 原数据有 3041 行,性别字段只有两个取值,转长格式后有 2*3041 行
new.row.names = 1:(2 * 3041),
direction = "long"
)# 数据重塑前
head(USCancerRates) # 宽格式
# rate.male LCL95.male UCL95.male rate.female LCL95.female
# alabama,pickens 363.7 311.1 423.2 151.0 123.6
# alabama,bullock 345.7 274.2 431.4 140.5 102.8
# alabama,russell 340.7 304.5 380.9 182.3 161.3
# alabama,barbour 335.9 288.9 389.1 185.3 157.2
# alabama,dallas 330.1 293.4 370.6 172.0 151.4
# alabama,greene 328.1 255.9 416.6 124.1 88.5
# UCL95.female state county
# alabama,pickens 183.6 Alabama Pickens County
# alabama,bullock 189.7 Alabama Bullock County
# alabama,russell 205.5 Alabama Russell County
# alabama,barbour 217.5 Alabama Barbour County
# alabama,dallas 195.0 Alabama Dallas County
# alabama,greene 171.7 Alabama Greene County
# 数据重塑后
head(us_cancer_rates, 12) # 长格式
# state county sex LCL95 rate UCL95
# 1 Alabama Pickens County 男性 311.1 363.7 423.2
# 2 Alabama Bullock County 男性 274.2 345.7 431.4
# 3 Alabama Russell County 男性 304.5 340.7 380.9
# 4 Alabama Barbour County 男性 288.9 335.9 389.1
# 5 Alabama Dallas County 男性 293.4 330.1 370.6
# 6 Alabama Greene County 男性 255.9 328.1 416.6
# 7 Alabama Perry County 男性 261.4 327.9 408.0
# 8 Alabama Walker County 男性 299.1 327.4 358.2
# 9 Alabama Macon County 男性 276.4 323.6 377.5
# 10 Alabama Lamar County 男性 265.3 321.4 386.3
# 11 Alabama Lawrence County 男性 276.1 318.5 366.9
# 12 Alabama Marengo County 男性 267.4 315.6 370.7# 从 usmapdata 包获取地图数据
county_df <- usmapdata::us_map("counties")
# 给每个郡的癌症死亡率数据配上地图数据
dat <- merge(
x = county_df, y = us_cancer_rates,
by.x = c("full", "county"),
by.y = c("state", "county"),
all.y = T
)
# 准备州边界线数据
state_df <- usmapdata::us_map("states")
# 癌症死亡率分级
dat$rate_d <- cut(dat$rate, breaks = 50 * 0:13)
# 恢复地图数据顺序
dat <- dat[order(dat$order), ]数据准备工作完成后,绘图过程主要有八个步骤:
- 底图:绘制美国郡地图,填充灰色背景,以此为底图。
- 映射:添加每个郡的癌症死亡率数据,填充颜色根据死亡率而定。同时以浅白色绘制郡的边界线,将线调细一些,与后面州的边界线形成层次。
- 边界:添加美国各个州的边界线,帮助熟悉美国地图的读者从州到郡快速定位。
- 配色:类似前文设置,采用
plasma调色板,未采集到死亡率数据的郡填充灰色,和地图背景融为一体。 - 布局:以函数
facet_wrap()实现分面,分面标题放在图形上方,布局为两行一列。 - 标题:添加整个图形的主标题、副标题和图例标题。
- 主题:设置整个图形主题样式
theme_void()以符合地图特色,将图形主标题位置居中。 - 细节:打磨图形配色、长宽尺寸、字体大小等方面,直至满意。
library(ggplot2)
ggplot() +
geom_polygon(
data = county_df, aes(x, y, group = group),
fill = "grey80"
) +
geom_polygon(
data = dat, aes(x, y, group = group, fill = rate_d),
colour = alpha("white", 1 / 4), size = 0.1
) +
geom_polygon(
data = state_df, aes(x, y, group = group),
colour = "gray80", fill = NA, size = 0.15
) +
scale_fill_viridis_d(option = "plasma", na.value = "grey80") +
facet_wrap(~sex, ncol = 1, strip.position = "top") +
labs(
fill = "死亡率", title = "1999-2003 年美国各个郡的年平均癌症死亡率",
caption = "数据源:美国国家癌症研究所"
) +
theme_void(base_size = 13) +
theme(plot.title = element_text(hjust = 0.5))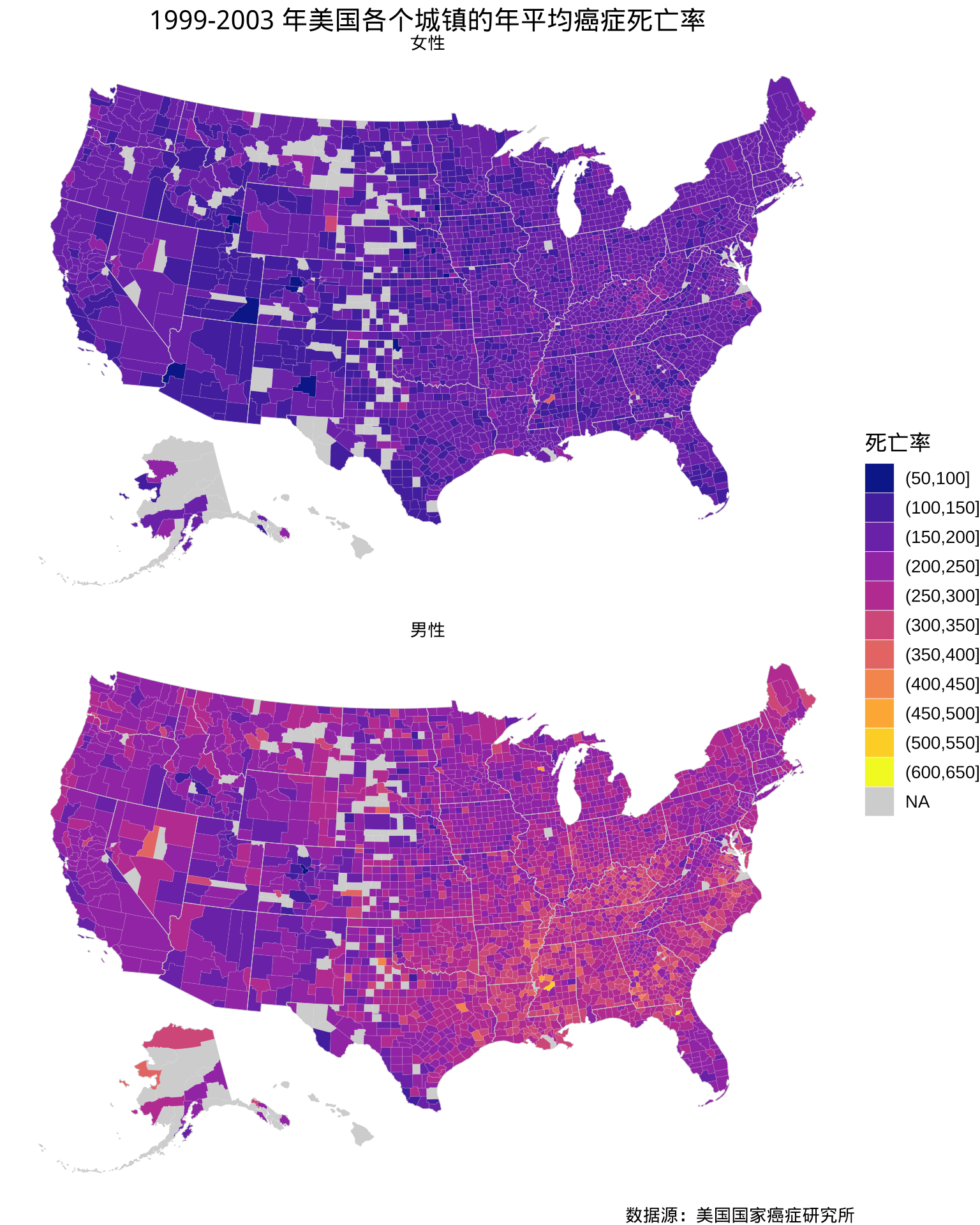
图 2.7: 1999-2003 年美国各个郡的年平均癌症死亡率分布
尽管已经调整了上图2.7的长宽比例,可一旦和非 ggplot2 绘制的图形对比,就可以看出明显变形了。
2.1.4 tmap
同 sf 包[6]的绘图函数 plot() 一样,tmap [5] 也是基于 Base R 图形系统,但使用语法更加贴合 ggplot2 包[4],对空间数据可视化有更多专业支持,比如基于比例的符号/气泡图[17] 1和基于二维核密度估计的热力图[5]。
tmap 支持 sp 包提供的 Spatial 类数据对象,也支持 sf 包提供的 Simple Features 类数据对象,后者是新一代更好的工具,因此接下来的示例都将基于 sf 包。首先从美国人口调查局下载州和郡级别的多边形边界数据,再类似 usmapdata 包对阿拉斯加、夏威夷和波多黎各做适当的调整,借助 tidycensus 包[18]让这个过程变得容易,调整地图数据的代码与源文档放在一起,读者可自取。
# 准备地图数据
library(sf)
us_state_map <- readRDS(file = "data/us_state_map.rds")
us_county_map <- readRDS(file = "data/us_county_map.rds")
# 重命名 fips_codes 的 state 列为 state_abbr
fips_codes <- within(tidycensus::fips_codes, {state_abbr = state})
fips_codes <- subset(x = fips_codes, select = setdiff(colnames(fips_codes), "state"))
# 癌症死亡率数据关联州、郡代码 FIPS
us_cancer_rates <- merge(
x = us_cancer_rates,
y = fips_codes,
by.x = c("state", "county"),
by.y = c("state_name", "county"),
all.x = TRUE
)
# 合并地图数据和观测数据
us_county_cancer2 <- merge(
x = us_county_map, y = us_cancer_rates,
by.x = c("STATEFP", "COUNTYFP"),
by.y = c("state_code", "county_code"), all.x = TRUE
)准备好数据后,绘图过程比较类似之前使用 ggplot2 绘图,所不同的是,添加了指北针、比例尺等地区分布图特有的内容。
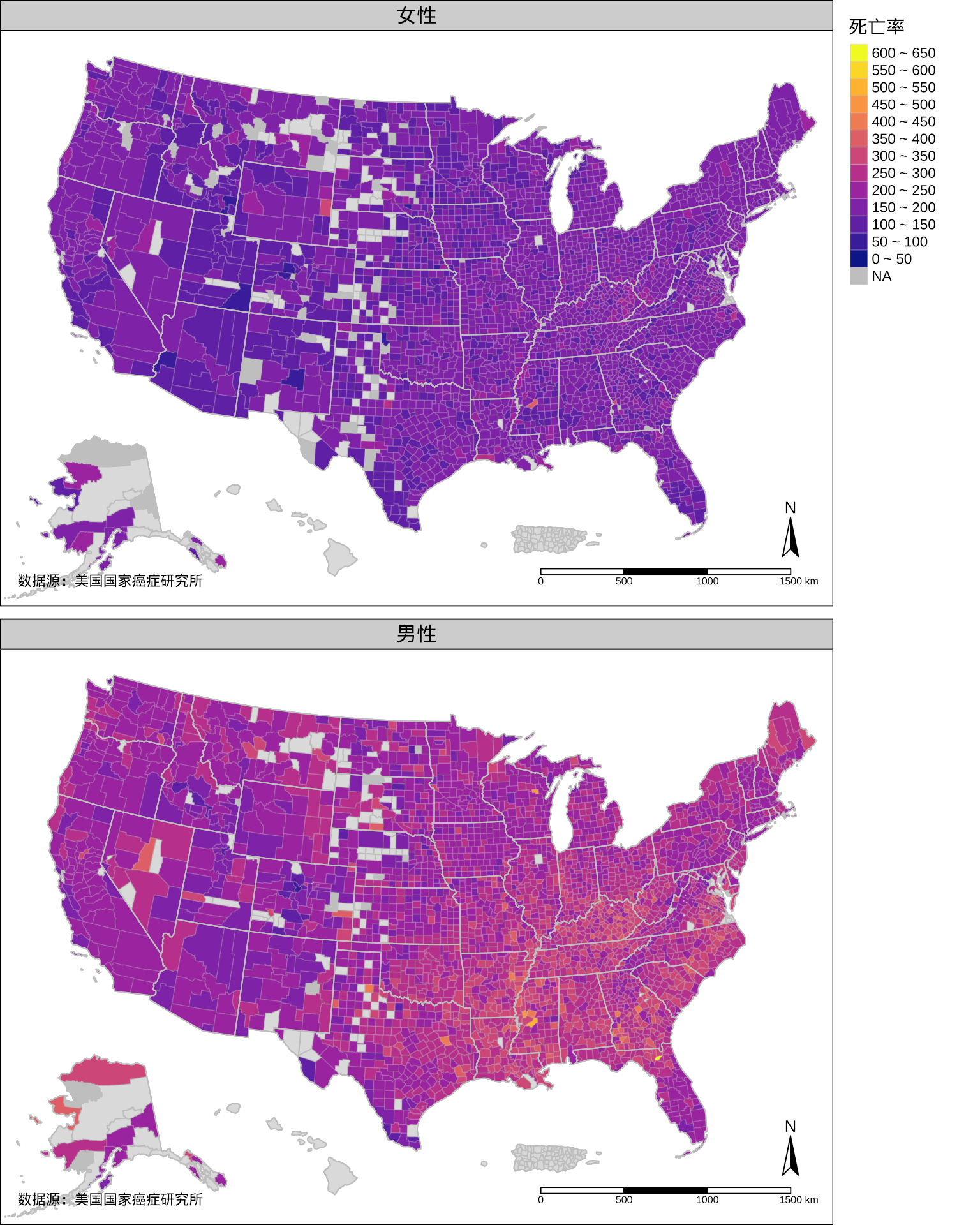
图 2.8: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
# 绘图
tmap::tm_shape(us_county_cancer2) +
tmap::tm_polygons(border.col = "gray") +
tmap::tm_shape(us_county_cancer2) +
tmap::tm_polygons(
col = "rate",
palette = "plasma", border.alpha = 0.2,
legend.reverse = TRUE, title = "死亡率",
colorNA = "gray",
textNA = "NA", border.col = "gray",
breaks = 50 * 0:13
) +
tmap::tm_facets(by = "sex", drop.NA.facets = T, ncol = 1) +
tmap::tm_shape(us_state_map) +
tmap::tm_polygons(col = NA, border.col = "gray", alpha = 0) +
tmap::tm_compass(position = c("right", "bottom")) +
tmap::tm_scale_bar(position = c("right", "bottom")) +
tmap::tm_credits(text = "数据源:美国国家癌症研究所", position = "left") +
tmap::tm_layout(
legend.outside = TRUE,
legend.outside.position = "right",
legend.outside.size = 0.15,
legend.format = list(text.separator = "~"),
outer.margins = 0,
asp = 0
)2.1.5 sf
在上一节已经准备好了美国各个郡的边界数据,接下来合并各个郡的癌症死亡率数据 USCancerRates,调用 sf 包[6]的绘图函数 plot()。除了调用函数 plot()的几行代码,绘制图2.9的代码和前面调用 maps 包绘图大体是类似的,但灵活性高得多,因 sf 包的强大,支持大量的空间数据存储格式,不受限于 maps 包内置的不完整地图数据,也不因给郡区域上色添加额外的数据匹配操作。
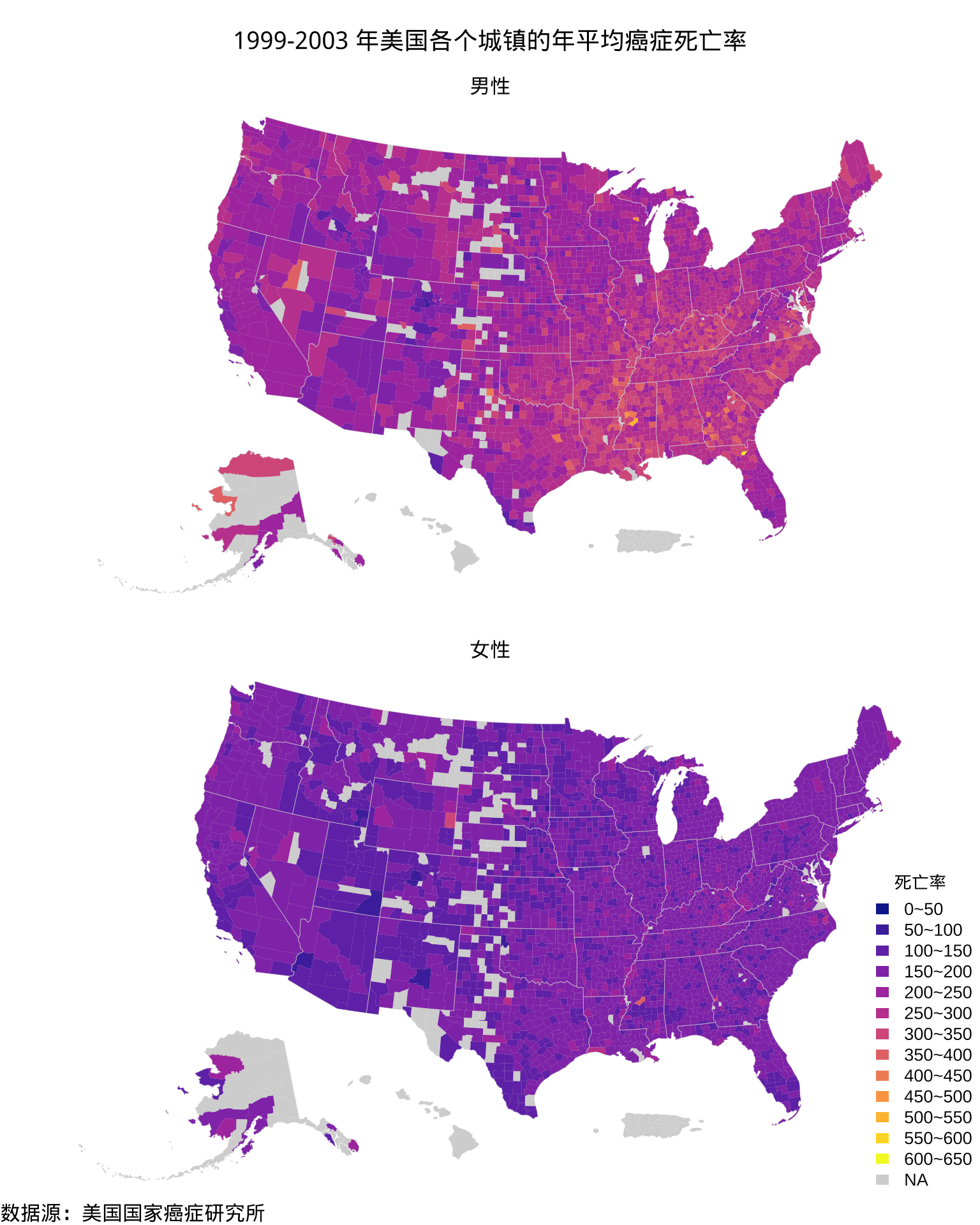
图 2.9: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
# 癌症死亡率数据关联州、郡代码
USCancerRates2 <- merge(
x = USCancerRates,
y = fips_codes,
by.x = c("state", "county"),
by.y = c("state_name", "county"),
all.x = TRUE
)
# 空间数据合并观测数据
us_county_cancer <- merge(
x = us_county_map, y = USCancerRates2,
by.x = c("STATEFP", "COUNTYFP"),
by.y = c("state_code", "county_code"),
all.x = TRUE
)
par(mar = c(0, 0, 4, 0), mfrow = c(2, 1))
# 添加郡地图
plot(st_geometry(us_county_map),
reset = FALSE, border = NA, col = "grey80", main = ""
)
# 添加癌症死亡率数据
plot(us_county_cancer["rate.male"],
pal = viridisLite::plasma, reset = FALSE, key.pos = NULL,
breaks = 50 * 0:13,
border = NA, lwd = 0.25, add = TRUE
)
# 美国各个州边界
plot(st_geometry(us_state_map), border = "gray80", lwd = 0.25, add = TRUE)
# 添加主标题
title(main = "1999-2003 年美国各个郡的年平均癌症死亡率", line = 2)
# 添加分面标题
mtext(text = "男性", side = 3, adj = 0.5)
# 调整边空
par(mar = c(1, 0, 2, 0))
plot(st_geometry(us_county_map),
reset = FALSE, border = NA, col = "grey80", main = ""
)
plot(us_county_cancer["rate.female"],
pal = viridisLite::plasma, reset = FALSE, key.pos = NULL,
breaks = 50 * 0:13,
border = NA, lwd = 0.25, add = TRUE
)
plot(st_geometry(us_state_map), border = "gray80", lwd = 0.25, add = TRUE)
mtext(text = "女性", side = 3, adj = 0.5)
mtext(text = "数据源:美国国家癌症研究所", side = 1, adj = 0)
# 调色板
colors <- viridisLite::plasma(13)
# 图例文本
leg.txt <- mapply(paste, 50 * 0:12, 50 * 1:13, collapse = " ", sep = "~")
# 添加图例
legend("bottomright",
legend = c(leg.txt, "NA"), title = "死亡率", box.col = NA, border = NA,
horiz = FALSE, fill = c(colors, "grey80"), cex = 0.85, xjust = 0.5
)2.1.6 ggplot2 + sf
ggplot2 截止当前最新版本,ggplot2 在空间数据可视化都是非常不专业的,最糟糕的一个点是它会将地图弄变形了。 尽管ggspatial [19] 在 ggplot2 的基础上补充了一些地图特有的元素,如比例尺、指北针,但并没有解决地图变形的核心问题。正如 Roger Bivand 所言,还有其它可能难以预料的问题:
For visualisation, please avoid using ggplot2 unless you use this package often (daily). For thematic mapping, tmap and mapsf are to be preferred, because they are written for making maps. Do not simplify/generalise coastlines unless you really need to do so. You can use tmap and mapview to view thematic maps interactively - as you zoom in, you see artefacts created by line generalization.
因此,尽管 ggplot2 包已经流行开来,并且在很多方面取得成绩,但严格来说,不推荐使用 ggplot2 包来绘制任何和地图相关的图形,除非很清楚研究区域的情况,即在合适的地理区域采用合适的投影、合适的工具绘制准确的地理图形。ggplot2 在 2018 年发布 3.0.0 版本,开始借助 sf 包支持 Simple Features 数据对象的绘图,这就一定程度上缓解了地图变形的问题。
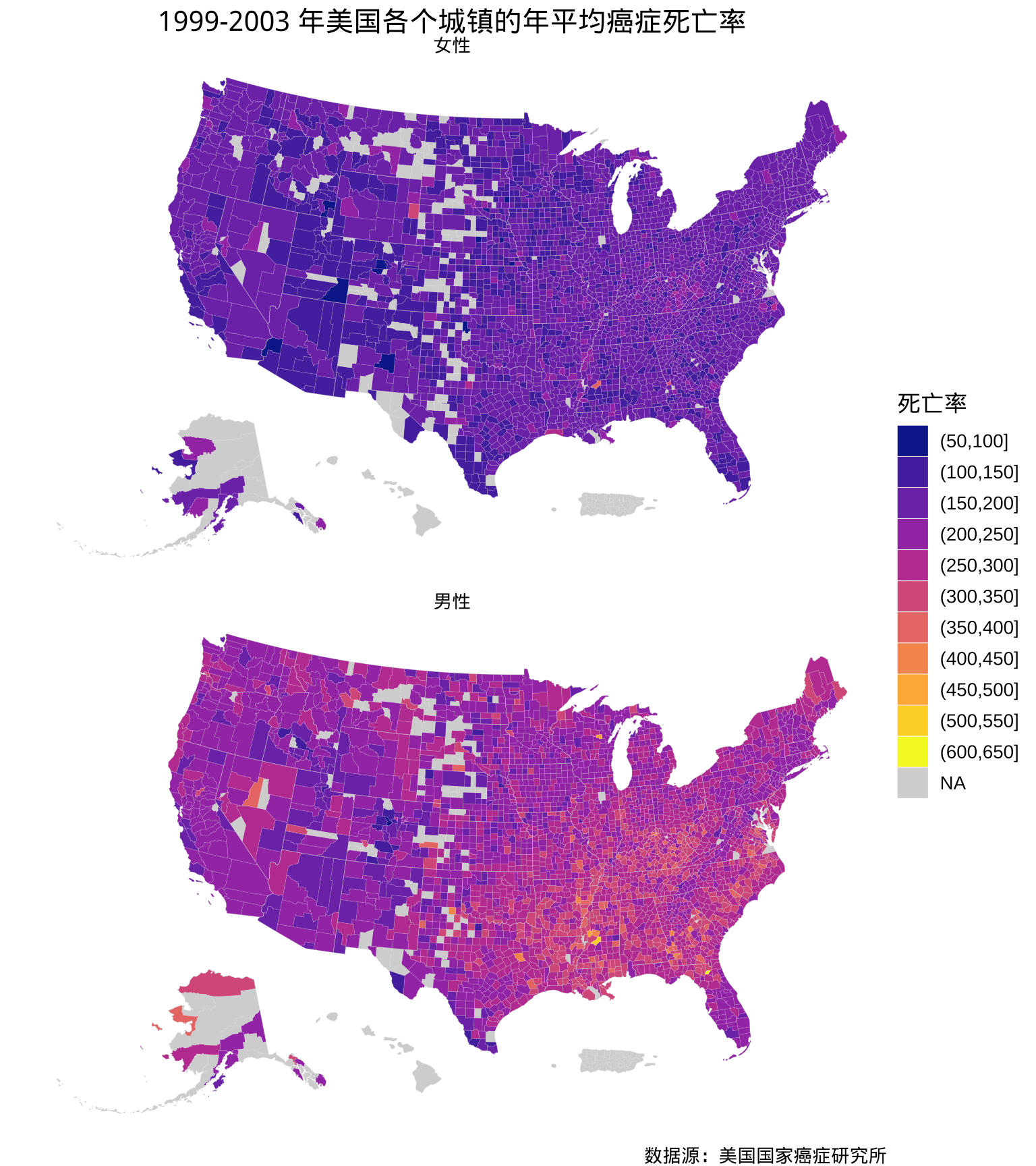
图 2.10: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
us_county_cancer2$rate_d <- cut(us_county_cancer2$rate, breaks = 50 * 0:13)
ggplot() +
geom_sf(
data = us_county_map,
fill = I("grey80"), colour = NA
) +
geom_sf(
data = us_county_cancer2[!is.na(us_county_cancer2$sex), ],
aes(fill = rate_d), colour = alpha("white", 1 / 4), size = 0.1
) +
geom_sf(
data = us_state_map,
colour = alpha("gray80", 1 / 4), fill = NA, size = 0.15
) +
scale_fill_viridis_d(option = "plasma", na.value = "grey80") +
coord_sf(crs = st_crs("ESRI:102003")) +
facet_wrap(~sex, ncol = 1) +
labs(
fill = "死亡率", title = "1999-2003 年美国各个郡的年平均癌症死亡率",
caption = "数据源:美国国家癌症研究所"
) +
theme_void(base_size = 13) +
theme(plot.title = element_text(hjust = 0.5))2.1.7 mapsf
如 Roger Bivand 所推荐,下面介绍 mapsf 包 [7],它在 sf 包的基础上添加更多地理可视化的功能,比如指北针、比例尺、三维特效等,同时也支持比例符号图、地区分布图及其混合地图。mapsf 绘图思路和 sf 是一致的,只是封装了一些更加便捷的绘图函数,如图2.11所示,大体分三步:其一准备主题样式,配色、布局等;其二表达地理数据,选择合适的图形,建立数据到地图的映射;其三补充一些说明,如注释、比例尺、标题等。
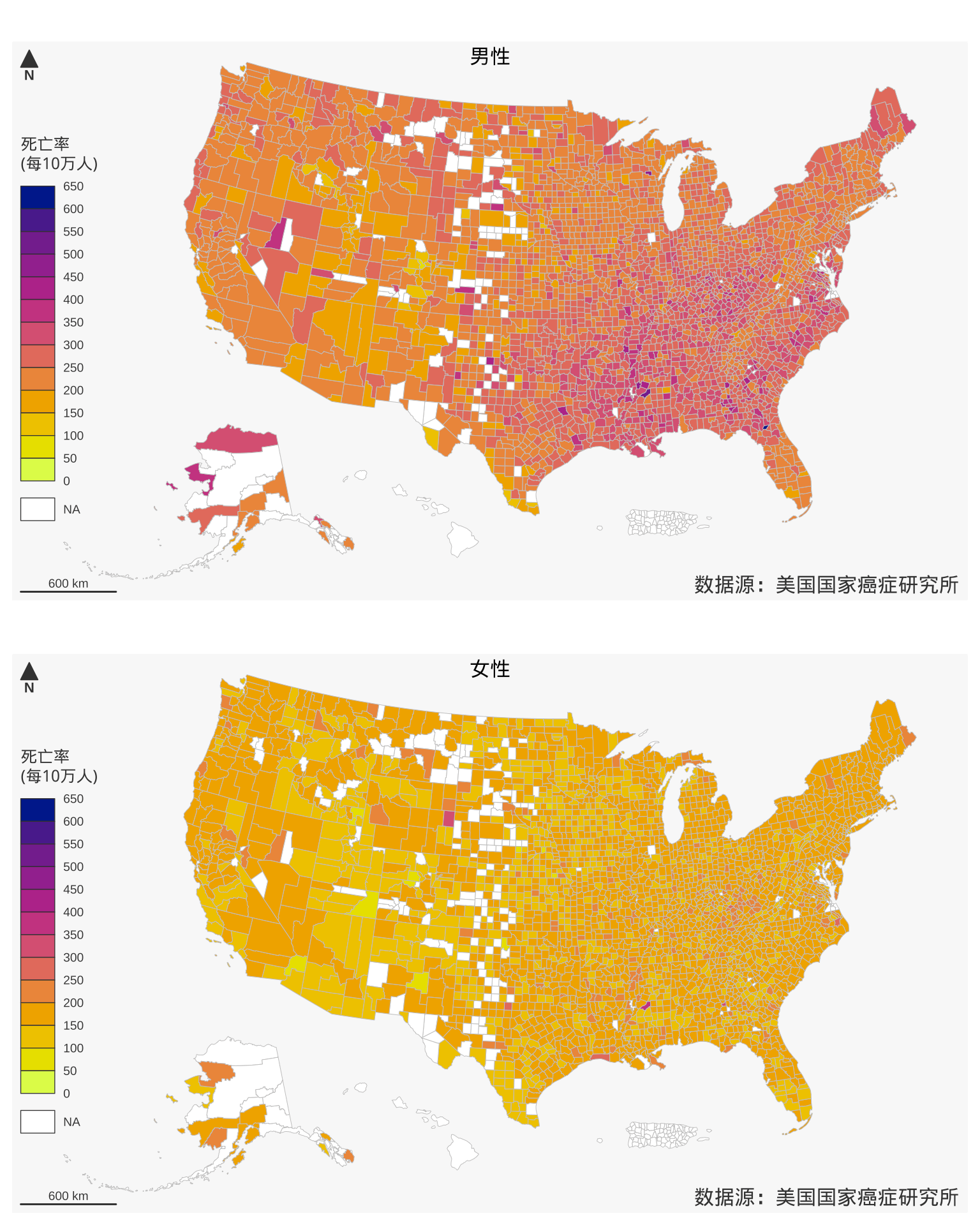
图 2.11: 1999-2003 年美国各个郡的年平均癌症死亡率分布
点击显示或隐藏代码
library(mapsf)
par(mfrow = c(2, 1))
# 设置主题
mf_theme("default", inner = TRUE, tab = TRUE, pos = "center")
# 绘制地图
mf_map(
x = us_county_cancer,
var = "rate.male",
type = "choro",
breaks = 50 * 0:13,
pal = "Plasma",
border = "gray",
lwd = 0.5,
leg_val_rnd = 0,
leg_pos = "left",
leg_no_data = "NA",
leg_title = "死亡率\n(每10万人)"
)
# 指北箭头
mf_arrow(pos = "topleft")
# 比例尺
mf_scale(pos = "bottomleft")
# 标题
mf_title(txt = "男性", bg = "#f7f7f7", fg = "black", cex = 1)
# 出处
mf_credits(txt = "数据源:美国国家癌症研究所", pos = "bottomright", cex = 1)
mf_map(
x = us_county_cancer,
var = "rate.female",
type = "choro",
breaks = 50 * 0:13,
pal = "Plasma",
border = "gray",
lwd = 0.5,
leg_val_rnd = 0,
leg_pos = "left",
leg_no_data = "NA",
leg_title = "死亡率\n(每10万人)"
)
mf_arrow(pos = "topleft")
mf_scale(pos = "bottomleft")
mf_title(txt = "女性", bg = "#f7f7f7", fg = "black", cex = 1)
mf_credits(txt = "数据源:美国国家癌症研究所", pos = "bottomright", cex = 1)mapsf 包函数 mf_map() 的参数 pal 可取自 R 内置的调色板 hcl.pals(),共计 115 个。设置调色板的内部函数 mapsf:::get_the_pal() 将原调色板 hcl.colors() 反向了,导致图2.11的整个配色和之前的图形有所不同,但这并不妨碍图形的准确性和美观性。
3 多变量情形
多元地区分布图用以同时展示两个具有空间相关性的变量,比如人均收入和预期寿命,房地产投资占比和城镇化率[1]。下面以美国北卡州家庭年收入与白人占比的空间相关性为例,在地区分布图上同时展示多个指标,除了用到 ggplot2 和 sf 包,还需 biscale [20]和 cowplot [21]两个包,前者构造多元变量分组,后者负责将图例和地图主体合并。R 社区最早的技术实现方案来自 Timo Grossenbacher 的博客Bivariate maps with ggplot2 and sf。
3.1 美国北卡州家庭年收入与白人占比的空间相关性
3.1.1 数据获取
受上个癌症死亡率地区分布图的启发,除了郡级别,还有社区普查级别的地区分布图,以描述更加精细的空间区域数据分布,同时,这次直接从美国人口调查局获取数据。数据来自 2015-2019 年度美国社区调查(American Community Survey,简称 ACS),每年约350万家庭的抽样,每年更新一次。本节使用的数据有:
- 北卡罗来纳州社区级家庭年收入,统计每个家庭过去12个月的收入,这相当于家庭年收入,再取社区内所有家庭年收入的中位数,众所周知,中位数比平均数更加稳定,更有代表性。家庭年收入已根据 2019 年的美国消费价格指数 CPI 调整,这样,各个年份的数据是有可比性的。
- 北卡罗来纳州社区级白人居民的百分比,美国除了白人,还有其它有色人种,且占比不小,分布广泛。
- 2019 年北卡罗来纳州郡级、社区级比例尺 1:500,000 多边形边界地图数据,2019 年美国州级、郡级比例尺 1:20,000,000 多边形边界地图数据。
美国人口调查局(US Census Bureau)提供数据 API 作为公共服务,Kyle Walker 为此开发了 R 接口 tidycensus 包[18],原始数据可借助 tidycensus 包从美国官方网站下载。下载数据之前,需要先注册一个访问令牌,保存到 R 环境变量 CENSUS_API_KEY,可在 .Renviron 文件中存储环境变量 CENSUS_API_KEY,以便后续调用。在网络一切都好的情况下,下载所需数据指标和北卡郡级、社区级地图数据非常简单,如下:
library(tidycensus)
library(sf)
# 郡级数据
nc_income_race_county <- get_acs(
state = "NC", # 北卡州
geography = "county", # 郡级
# 三个数据指标:家庭年收入,白人数量,总人数
variables = c("B19013_001", "B02001_001", "B02001_002"),
geometry = TRUE, # 下载北卡郡级地图数据
output = "wide", # 输出宽格式数据
year = 2019, # 2015-2019 年度
survey = "acs5", # 5 年
moe_level = 90 # 置信水平 90%
)
# 社区级数据
nc_income_race_tract <- get_acs(
state = "NC",
geography = "tract", # 社区级
variables = c("B19013_001", "B02001_001", "B02001_002"),
geometry = TRUE, output = "wide",
year = 2019, survey = "acs5",
moe_level = 90
)
# 北卡州郡级地图数据
nc_county_map <- tigris::counties(state = 37, cb = T, year = 2019, class = "sf")
# 北卡州社区级地图数据
nc_tract_map <- tigris::tracts(state = 37, cb = T, year = 2019, class = "sf")数据下载后,保存为四个文件:
nc_income_race_county.rds北卡州郡级家庭年收入和白人数量。nc_income_race_tract.rds北卡州社区级家庭年收入和白人数量。nc_county_map.rds北卡州郡级地图数据。nc_tract_map.rds北卡州社区级地图数据。
下面补充几个细节:
不同年份 ACS 调查的郡、社区有变化,美国也会定期更新地图数据,因此,北卡郡级、社区级地图数据的年份和 ACS 调查数据的发布年份要一致。
R 软件内置了数据集
state.name和state.abb,分别对应美国各个州的名称及其简称,tidycensus 包内置的数据集fips_codes还提供各州、郡的 FIPS 代码,用于下载所需州郡的数据。读者若对其它数据指标感兴趣,可通过如下命令查看:
acs_vars <- load_variables(year = 2019, dataset = "acs5") View(acs_vars)一共 27040 个指标,其中很多是衍生指标,比如上面用到的白人数量
B02001_001,人口数按种族分组统计,自然还可以有按性别、年龄分组的衍生指标。Kyle Walker 的著作《Analyzing US Census Data: Methods, Maps, and Models in R》[22] 提供了更多关于美国社区调查数据及其使用的介绍。
若网络不好,查看函数
get_acs()源码获取数据下载地址,打开浏览器从网页获取,嫌麻烦的话,直接用本文随附的数据吧。
在数据库中以合理的形式存储数以万计的指标,或者说一个不断变化的指标体系,需要考虑易用性和可扩展性。一般是以「长格式」存储的,表头包含:国家、地区(州、郡、社区等)、日期(年、月、日等)、指标ID、数值、指标描述等。这样,新增指标可以直接在表后面追加,不会因新增指标而新增列,影响稳定性,必要时以国家、地区等作为分区键还可以加快查询速度。
3.1.2 数据探索
The phenomenon external to an area of interest affects what goes on inside.
— Waldo Tobler [23]
在展示北卡州的数据之前,先看下美国各州、郡的收入分布概况,如图3.1 和图3.2 分别是美国州级、郡级的收入分布图,结合这两张图,不难看出除了少量的西岸加州一带城市和东岸波士顿、纽约、华盛顿一带城市,收入的空间分布较为平衡。北卡州的收入水平属于中等偏上,也算典型,境内分布的罗利、达勒姆、教堂山三座城市被称为东岸硅谷。北卡罗来纳大学有16个分校,俨然一个超大规模的大学城,教堂山分校的统计系是北美最早建立的统计系之一。
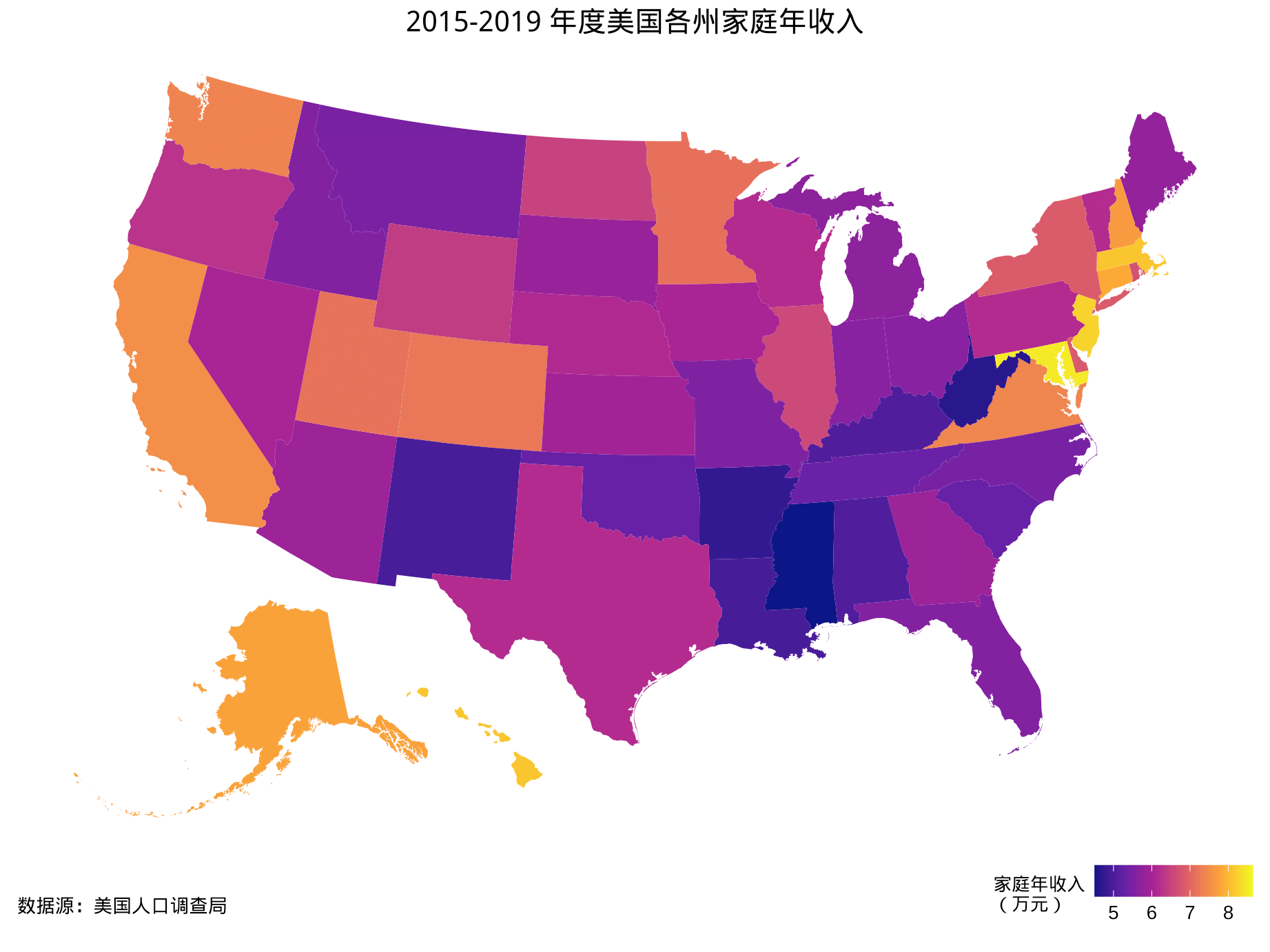
图 3.1: 2015-2019 年度美国各个州家庭年收入
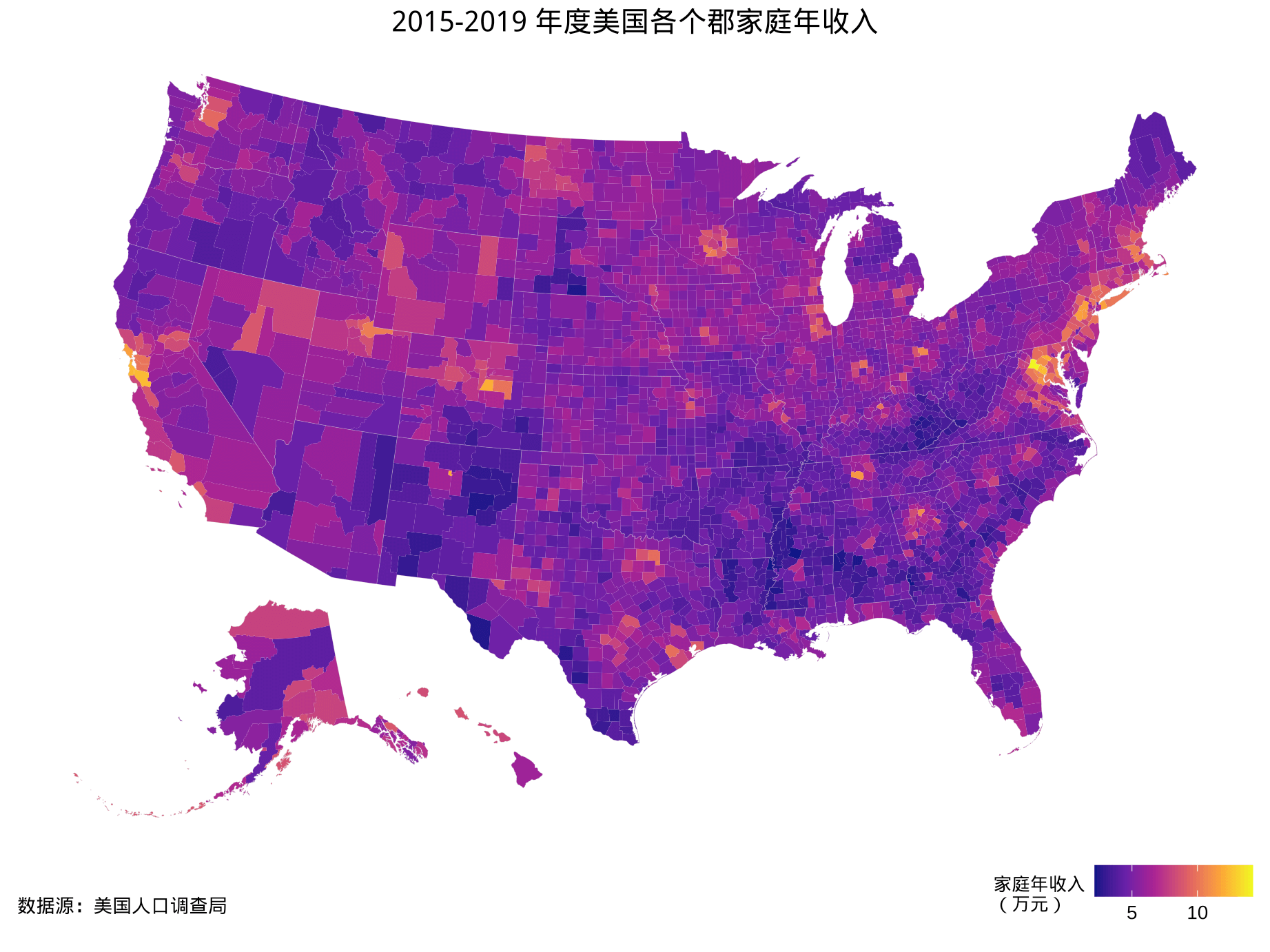
图 3.2: 2015-2019 年度美国各个郡家庭年收入
接下来,看下2015-2019年度美国北卡罗来纳州社区级家庭年收入的空间分布,如图3.3所示,图中空白处表示该区域的样本量太少或调查区域时间不连续,导致统计模型的估计不可用。结合图3.3,从空间上看,高收入和低收入群体有明显的圈层,在图中高亮的地区(也可以叫城镇),低收入社区穿插在高收入社区中,且有清晰的穿插线。
# 读取数据
nc_income_race_county <- readRDS(file = "data/nc_income_race_county.rds")
nc_income_race_tract <- readRDS(file = "data/nc_income_race_tract.rds")
# 计算家庭年收入和白人占比数据
nc_income_race_tract <- within(nc_income_race_tract, {
pop <- B02001_001E
pctWhite <- B02001_002E / B02001_001E
medInc <- B19013_001E
})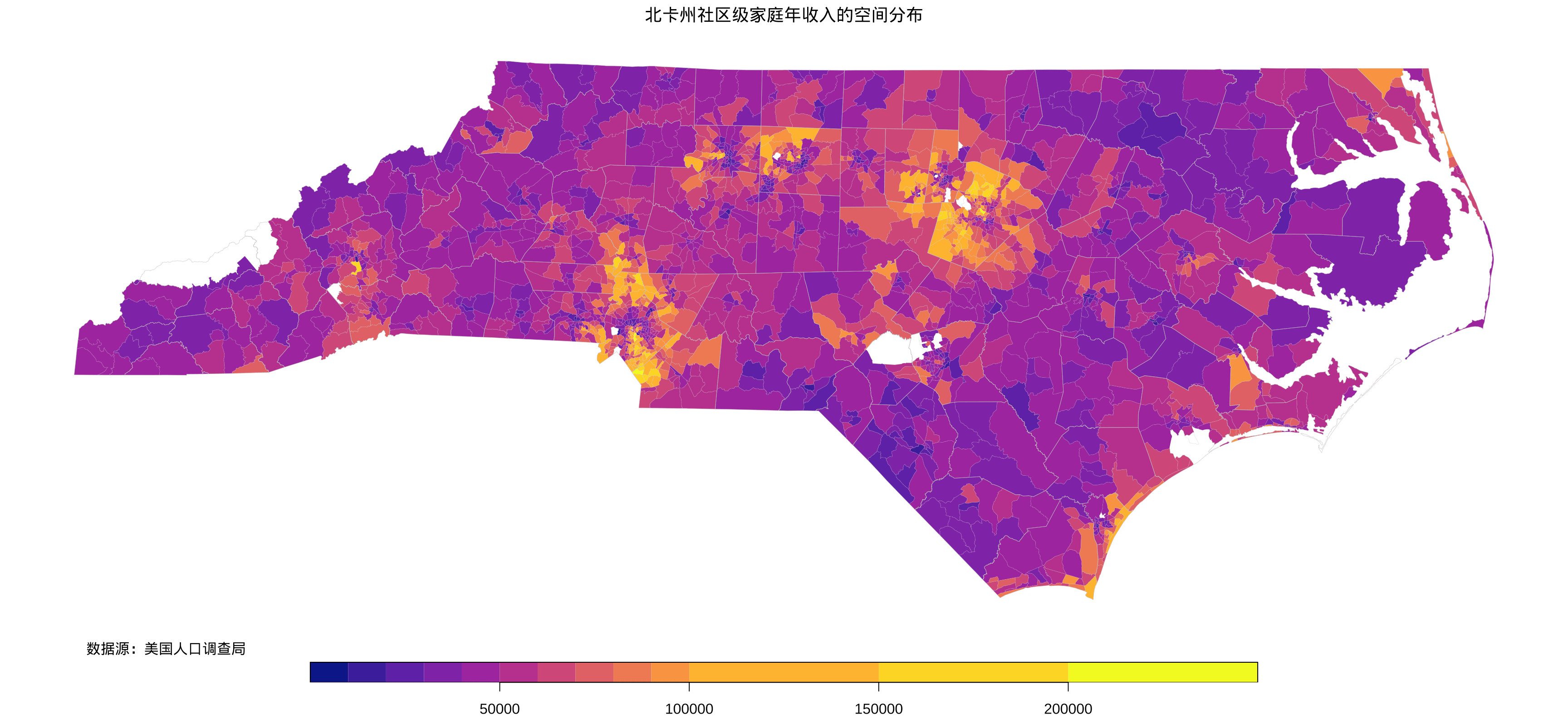
图 3.3: 北卡州社区级家庭年收入的空间分布
如图 3.4 所示,2015-2019 年度 ACS 调查,北卡州一共划分 2195 个社区,除了 36 个没有收集到收入数据的社区外,北卡州超过一半的社区家庭年收入超过 50000 美元,中位数是 51439 美元,图中三条红线分别是 25%,50% 和 75% 分位点。
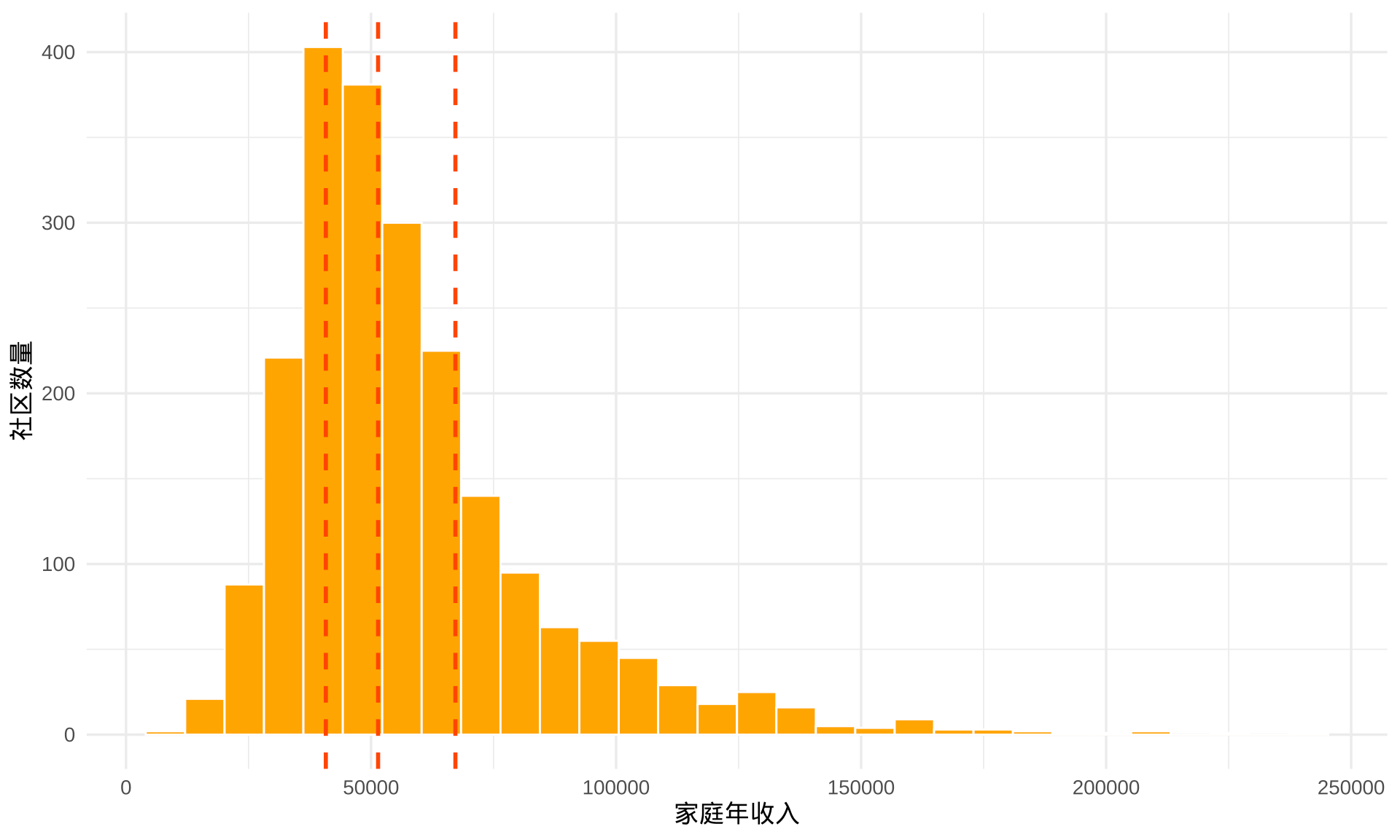
图 3.4: 北卡州社区级家庭年收入的分布
如图 3.5 所示,全州大部分社区人口数 10000 以内,极少的社区人口在 15000 以上。图中紫黑色表示人口数为 0,因社区人口太少或区域在时间上不连续导致模型无法给出估计。
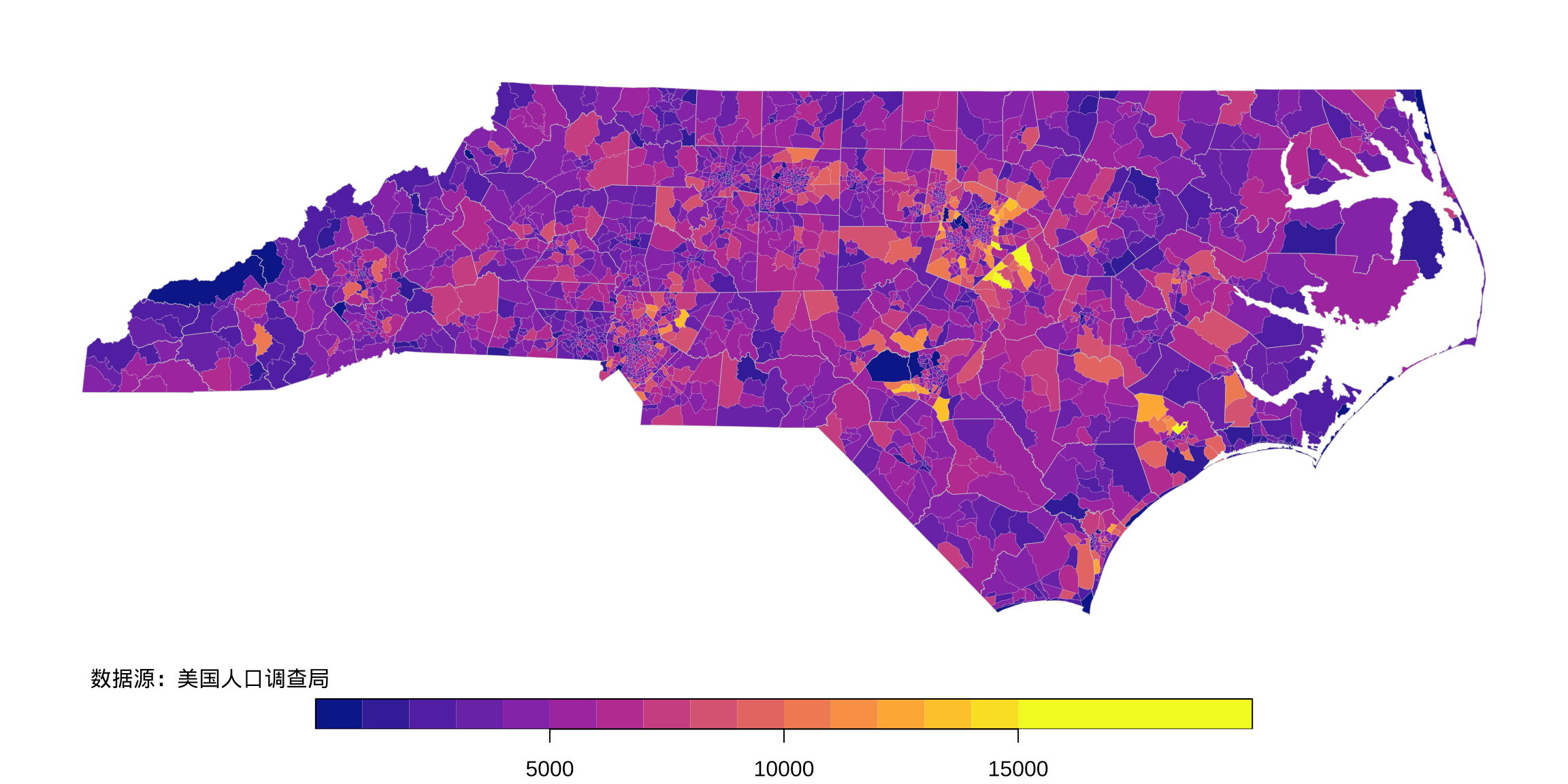
图 3.5: 北卡州社区级人口的空间分布
如图3.6所示,北卡州超过一半的社区人口数不足 5000,中位数是 4389,图中三条红线分别是 25%,50% 和 75% 分位点。ACS 调查会根据人口密度划分采样区,人口密度越高的城市采样区越多,反之,采样区越少。若某些区域的人口密度不断增大,还要继续拆分,一旦拆分,两次调查的空间划分就不一样了,就会出现局部地区不可比。整体上,每个采样区的人口数应在 1200-8000,最好在 4000 人,以便抽样调查的样本比较均衡,方便后续模型估计,更多内容详见帮助文档?tigris::tracts。
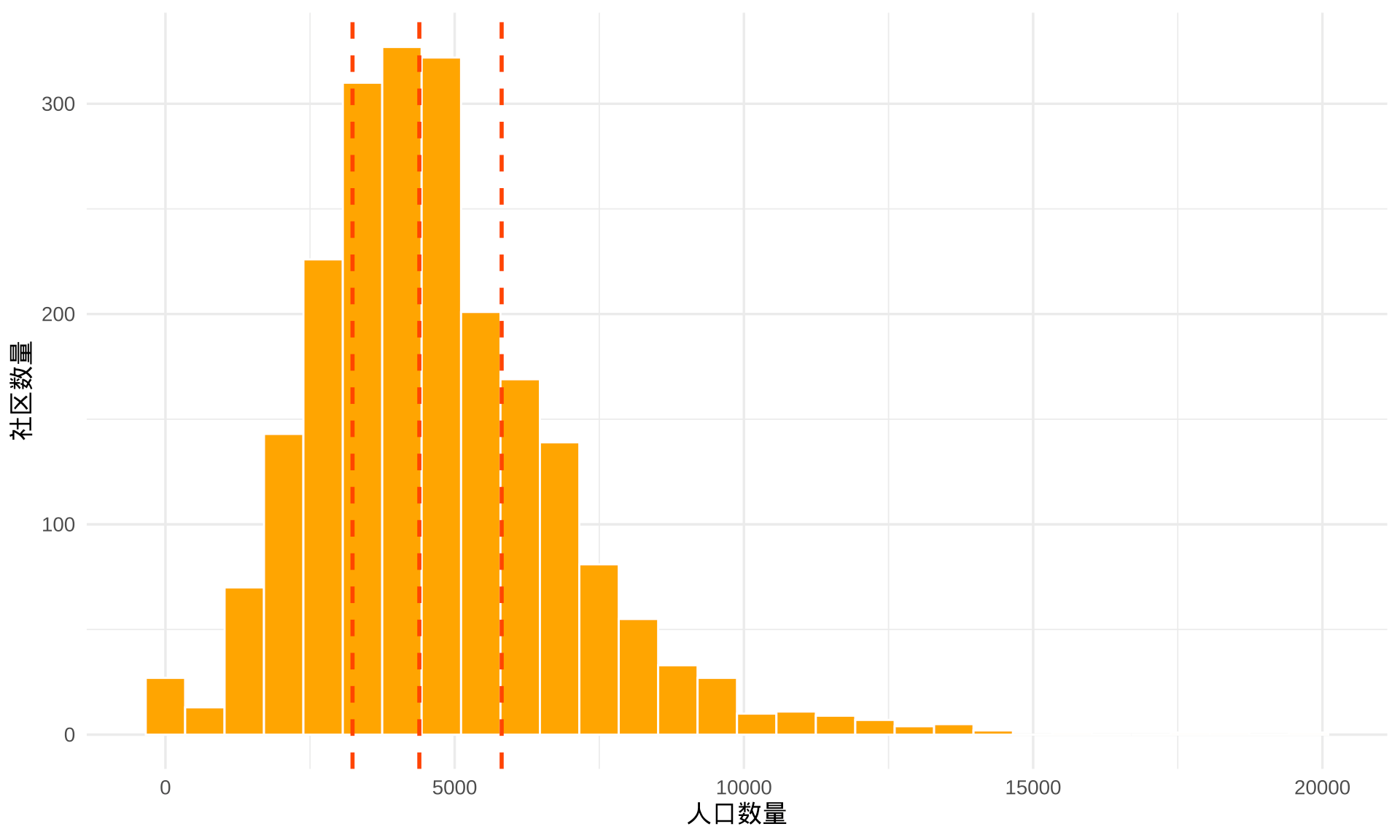
图 3.6: 北卡州社区级人口的分布
如图3.7所示,白人集中分布在东岸城市(北卡州的东部边缘,也是大西洋西岸)和北卡州的西部,整体上,白人占全州比例非常高,再结合图3.5,粗估也在 70%-80% 之间。
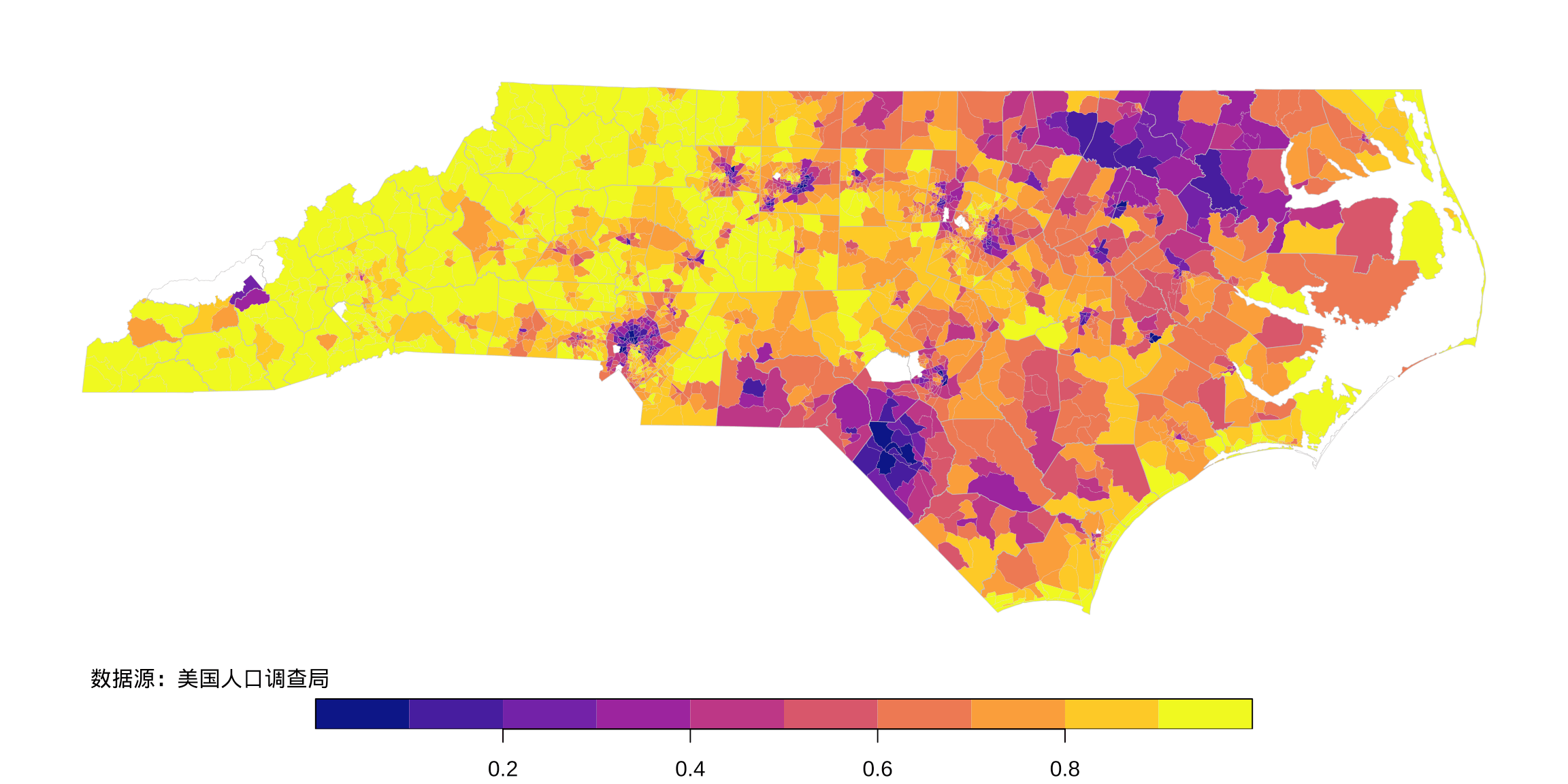
图 3.7: 北卡州社区级白人占比的空间分布
如图3.8所示,将家庭年收入和白人占比两个数据的分布联合起来看,融合了上图3.3和图3.7的数据信息。图中以白色块表示缺失数据。
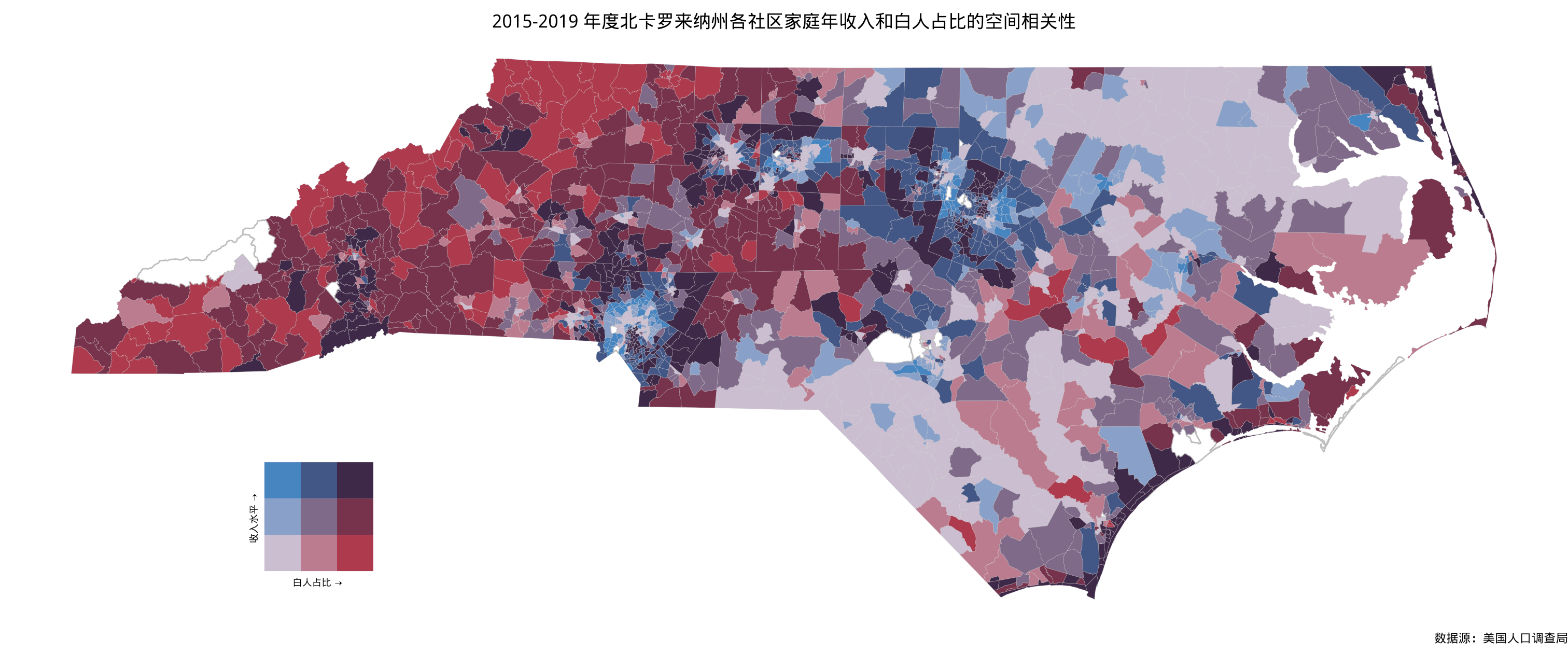
图 3.8: 2015-2019 年度北卡州社区级家庭年收入和白人占比的空间相关性
3.1.3 数据解读
继续社区级普查数据,先通过简单的线性模型粗估一下,家庭年收入和白人占比之间的关系:
\[ \mathrm{medInc} = \alpha + \mathrm{pctWhite} \cdot \beta \]
fit = lm(data = nc_income_race_tract, medInc ~ pctWhite)
summary(fit)
#
# Call:
# lm(formula = medInc ~ pctWhite, data = nc_income_race_tract)
#
# Residuals:
# Min 1Q Median 3Q Max
# -43312 -15651 -6136 8213 174442
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 27808 1652 16.8 <2e-16 ***
# pctWhite 43800 2271 19.3 <2e-16 ***
# ---
# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
# Residual standard error: 24900 on 2157 degrees of freedom
# (36 observations deleted due to missingness)
# Multiple R-squared: 0.147, Adjusted R-squared: 0.147
# F-statistic: 372 on 1 and 2157 DF, p-value: <2e-16根据调整的 \(R^2 = 0.147\),各社区家庭年收入和白人占比相关性比较低,结合图3.9也不难看出稳定正向的关系,平均来说,社区的白人占比增加一个百分点,该地区家庭平均年收入增加438美元。
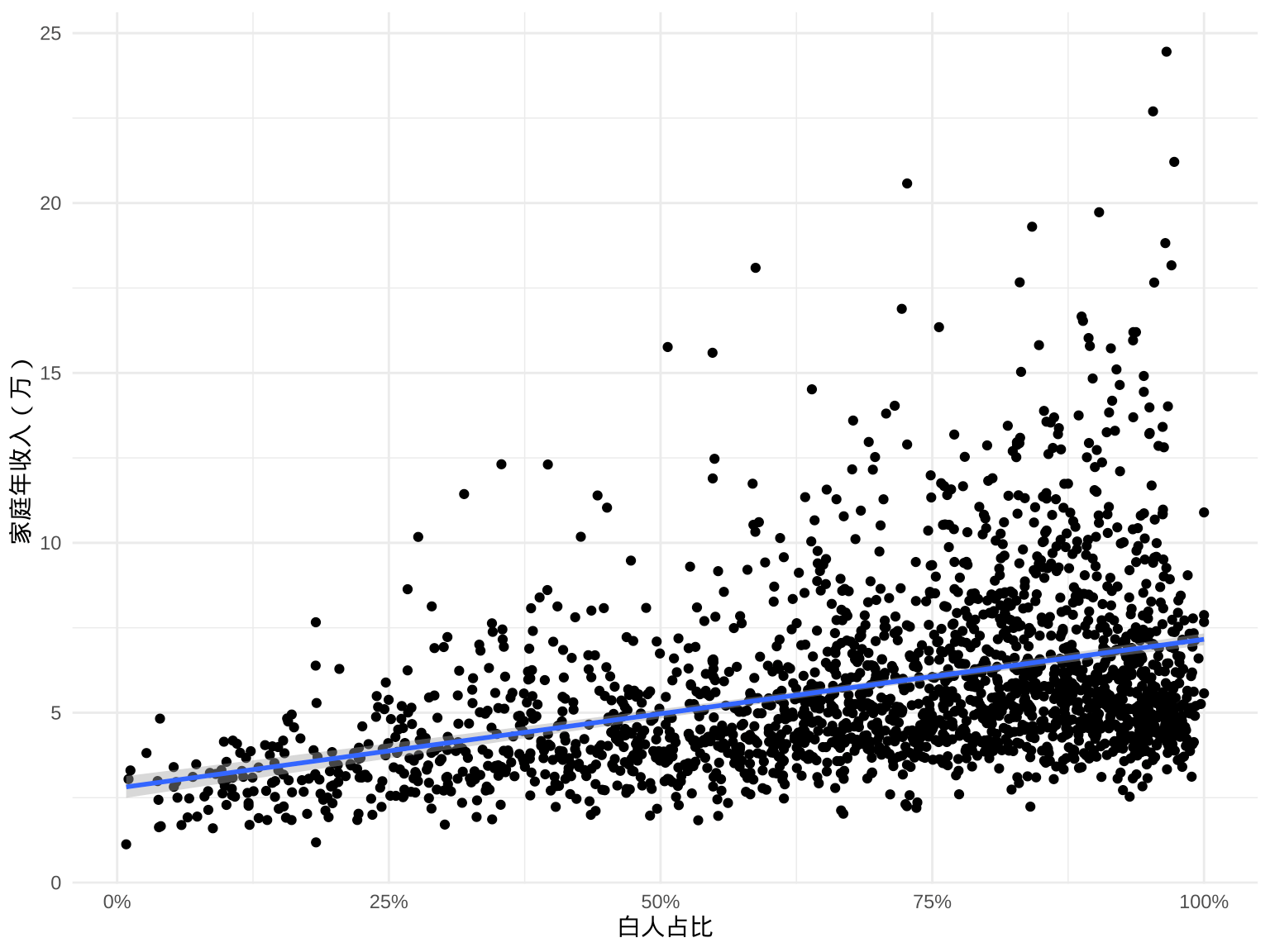
图 3.9: 家庭年收入和白人占比线性相关性
Everything is related to everything else, but near things are more related than distant things.
— Waldo Tobler [24]
接下来,回归到本节主旨:空间相关性。先来看下社区级家庭年收入的空间相关性,这可以用局部莫兰 I 指数刻画,可调 rgeoda包[25]计算,rgeoda 包站在libgeoda 和 GeoDa的肩膀上提供许多空间数据分析算法和模型。如图3.10所示,灰白色区域表示统计上空间聚集现象不显著,红色区域表示高收入显著的空间聚集现象,而大片的蓝色区域表示低收入显著的空间聚集现象。
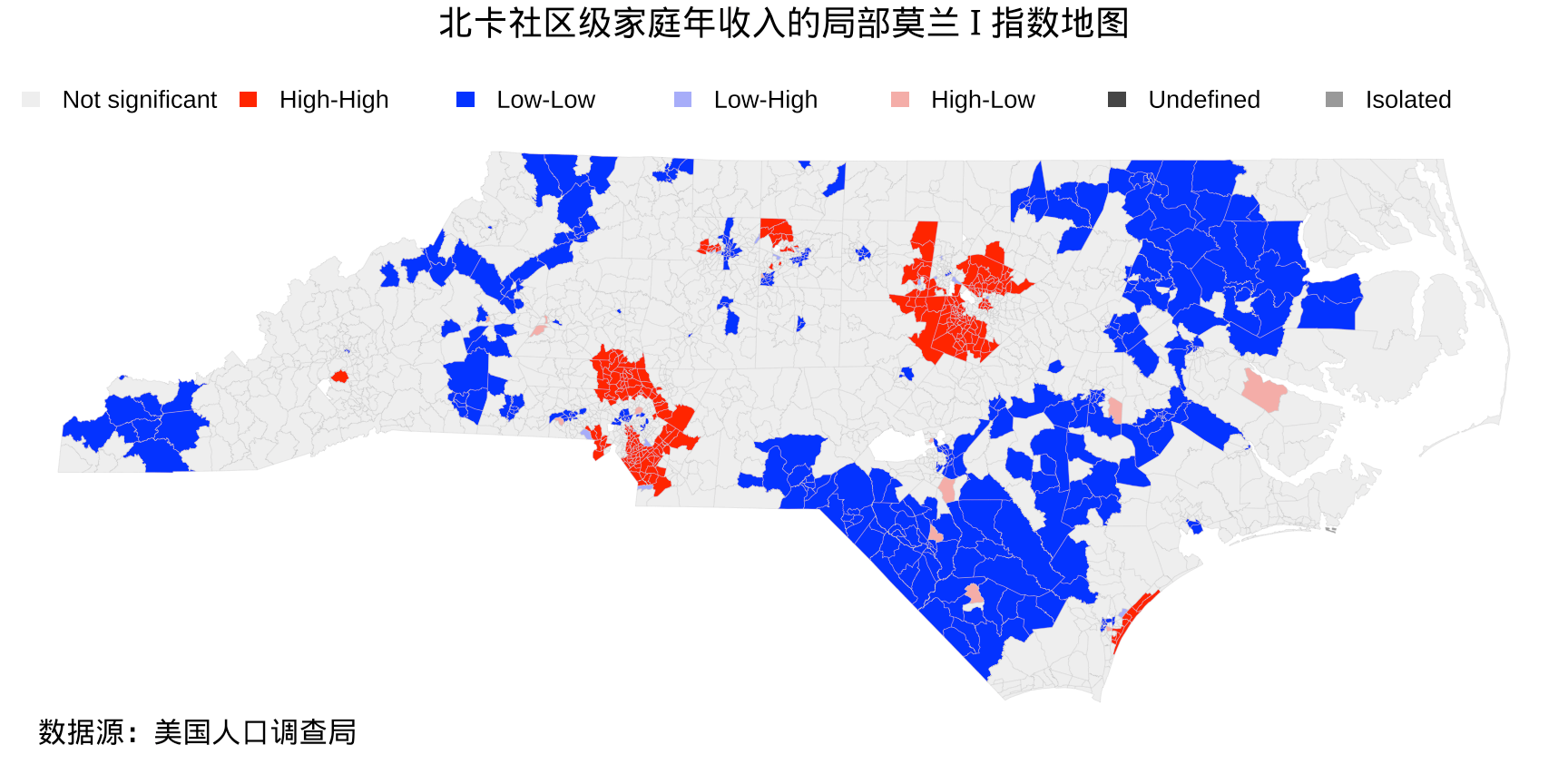
图 3.10: 北卡社区级家庭年收入的空间相关性
相比于图3.3,此图描述的空间结构清晰得多了,整体上,高收入的聚在一起,低收入的也聚在一起。高收入地区,其内圈是低收入,外圈也是低收入,高收入低收入一圈包一圈。结合图3.1,图3.2和图3.3,从州、郡、社区层层下钻和分析就可以看出收入不平衡的区域,以及精细的空间聚类模式。
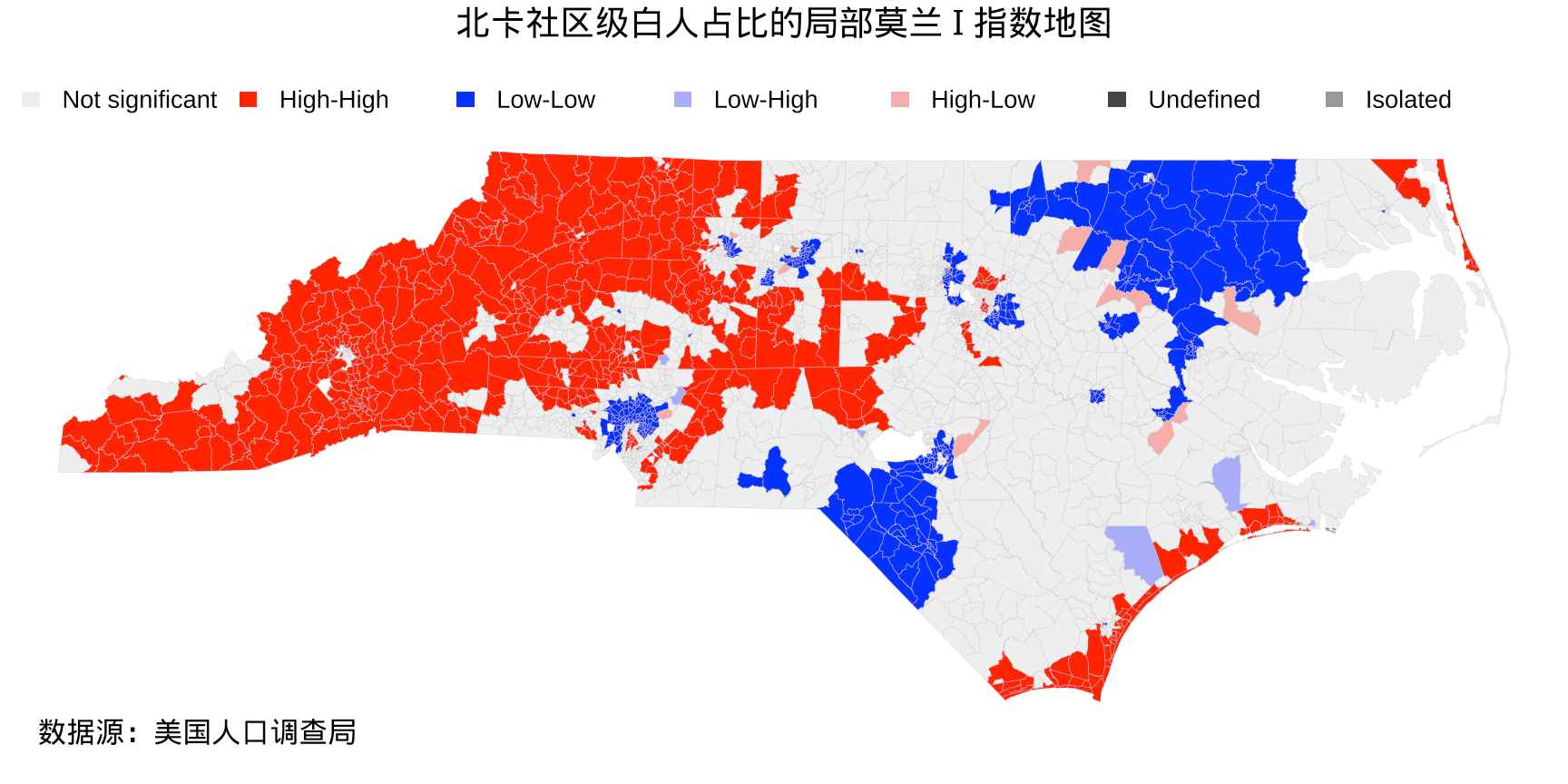
图 3.11: 北卡社区级白人占比的空间相关性
类似地,图3.11更清晰地描述白人在北卡的分布区域,结合收入分布图3.3和图3.10来看,收入越高的地区白人占比越高,由此可见,引入地区分布图帮助我们更直观地了解了白人占比和家庭收入的关系。
4 本文小结
本文以地区分布图为例,详细介绍 R 语言在绘制地区分布图中的探索和实践,读者可取其共性迁移至其它绘图场景。本文围绕 R 语言社区比较成熟的三套绘图工具 Base R、lattice 和 ggplot2 展开,它们代表三种绘图时的思考方式:
- Base R 提供了泛型函数
plot()支持各类数据对象,快速出图,若深度定制,需要解构,理解点、线、多边形、坐标轴、刻度线、图例、字体、颜色、文本、边空、布局等一系列基础要素。《现代统计图形》[26] 对此有详细的阐述,可做帮助手册。 - lattice 在 grid 图形系统的基础上构建了一套易于使用的高级数据可视化函数,同时支持复杂的非标准的自定义绘图需求。《lattice: Multivariate Data Visualization with R》[15] 详细全面地阐述了一元到多元数据的可视化方法,各个函数的使用细节,可做帮助手册。
- ggplot2 在 grid 图形系统的基础上实现了一套图形语法[27],笔者认为最重要的概念是图层,涵盖几何、统计、颜色、刻度、图例等,要点是将绘图的过程拆分成一个个图层,建立数据到图层的映射。《ggplot2: Elegant Graphics for Data Analysis》[4] 已经出到第三版了,是从入门到进阶全面介绍 ggplot2 的著作。
在掌握基础的一些工具后,需要培养审美能力,打磨细节,推荐学习著作《Data Visualisation with R: 111 Examples》[28]。
本文介绍的 7 种绘图方案都可归为上述三类,相关 R 包存在一些关联关系,如图4.1 所示,红色框代表 6 种绘图方案,外加 sf 强化的 ggplot2 升级方案。上层高级绘图函数不能一步到位就往下层走。比如用 latticeExtra 绘图就非常典型,添加图例标题使用了 grid 包,而添加州、郡边界线,用了更底层的面板函数 panel.lines()。没有哪个是不能做的,只是做的容易否?但凡是要像本文那样深度定制,似乎也没有哪个更容易的,因为都需要知道点、线、多边形、图例、标题、布局等基础元素,就看想要达到什么效果,有些效果已经满意了,比如文中 mapsf 包绘制的图2.11 或 sf 包绘制的图2.9,那就没必要再折腾了。

图 4.1: 7 种绘图方案依赖的 R 包及其层次关系
R 语言提供的公式语法大量存在于统计绘图和建模分析中,lattice 包提供非常简便的绘图公式语法,latticeExtra 也很好地继承了这一特性,如rownames(USCancerRates) ~ rate.female + rate.male。庆幸的是各郡癌症死亡率数据的郡名称rownames(USCancerRates) 和地图数据 us_county 里的郡名称 names 是可以映射上的,否则地区分布图就没法画了。lattice 包绘制图形,常常以层层嵌套的列表数据对象传递给参数来实现局部细节调整,这和一些基于 JavaScripts 的数据可视化库是不谋而合,前者是 R 中的 list 列表类型的数据对象,后者往往是一些 JSON 格式或键值对形式的数据对象。关键点是理解纵向的层次性和横向的互斥性,同层互斥不同层正交,稳扎稳打,不至于牵一发而动全身,掌握此规律,调整图的局部到调整代码的局部就建立好联系了。
ggplot2 绘图的理论基础是图形语法,将数据和几何元素建立映射关系,几何和统计图层层层叠加实现主体部分,辅以字体、颜色、坐标系、布局等实现精细调整,达到出版级的效果。图层的精妙之处在于符合 Unix 哲学 — Do one thing, and do it well! 整个复杂的图形拆解为一张张图层,每个图层干一件事,将复杂的过程简化下来。至于具体到地区分布图,因涉及到地图数据,情况稍微复杂一些,需要考虑地图数据和观测数据的坐标参考系,点、线、面(多边形或区域)数据类型,以及属于矢量还是栅格数据。总而言之,画个图,看似简单其实也透着综合能力:复杂过程的拆解能力,软件工具的熟练程度,领域知识的了解深度,难以言表的审美能力。
tmap 类似 mapsf,相比而言,上游依赖很多,相应功能也多,其Github站点有丰富的介绍材料。另一方面,据笔者在 MacOS 和 Ubuntu 系统上测试图2.8,发现绘图性能很差,这应该和它内部将 sf 等数据对象转化为 sp 数据对象有关。sp 已是上一代产品,现有工具足以替代,因此,不再介绍, [29] 推荐大家根据具体情况赶快迁移到新的空间数据工具箱 sf、stars [30] 或 terra [31],已成历史的三个 R 包 — 空间几何计算 rgeos [32]、空间数据导入 rgdal [33]和空间数据操作 maptools [34] 将于 2023 年底退休。
据笔者了解[35, 36],R 语言社区也有不少 R 包可以绘制交互版的地区分布图,比如 leaflet 包[37]、mapdeck 包[38]、plotly 包[39]和 echarts4r 包[40]等。配色是正文没有细谈的方面,在全文保持风格一致即可,若和数据背景相关就更好了。
5 未来展望
在单变量情形中,已用 7 种绘图方法展示美国各郡年平均癌症死亡率,还可以补充 ggplot2 + ggspatial 和 ggplot2 + maps 两种历史方法。
在多变量情形中,对美国社区调查数据,还可以继续做一些拓展分析,比如:
- 在社区级调查数据的基础上,分郡建立家庭年收入和白人占比的线性模型,获得各郡的相关性。进一步,将范围从北卡州扩展到全美,展示相关性在美国各郡的空间分布。
- 在线性模型的基础上,添加空间效应,引入空间自相关模型来量化家庭年收入与白人占比的空间分布。
- 基于过去 10-20 年的美国社区调查数据,分析高、低收入圈在空间集聚的过程和速度。
在应用方向上,还有很多有意思的场景,比如:

图 5.1: 美国各个郡新冠感染率,单位十万分之一
- 城市规划方面,龙瀛等创立北京城市实验室关注中国城市人口的收缩,如图5.2所示,在城市化进程中,2010年相比于2000年人口,区县级城镇人口变化,城市化进程是非常快的,城乡人口结构发生了根本性的变化。人口往长三角、珠三角等经济发达的地区集聚。城市的发展完全要靠人口集聚么?

图 5.2: 关注城市化进程中正在收缩的城市:蓝色表示人口收缩,红色表示人口扩张
在数据可视化上,还有很多技术方案,比如:

图 5.3: 左图:英国各个郡年龄中位数的空间分布;右图:英国各个郡新冠死亡率,单位十万分之一。
- Ilya Kashnitsky 和 Jonas Schöley 将人口划分为儿童(0-14岁)、青壮(15-64岁)、老年(大于65岁)三个年龄段,以三元结构图构造图例,编码欧洲各个地区的年龄结构,三个不同的主要色块分别代表三种典型的人口结构,如图5.4,一眼看上去好似一幅水彩画,非常有艺术感[42]。

图 5.4: 欧洲区域人口年龄结构
6 环境信息
本文是在 RStudio IDE 内用 R Markdown 编辑的,用 blogdown [43] 构建网站,Hugo 渲染 knitr 之后的 Markdown 文件,得益于 blogdown 对 R Markdown 格式的支持,图、表和参考文献的交叉引用非常方便,省了不少文字编辑功夫。点击本页面右上角「编辑本页」即可跳转至源文件,文中使用了多个 R 包,为方便复现本文内容,下面列出详细的环境信息:
xfun::session_info(packages = c(
"knitr", "rmarkdown", "blogdown",
"ggplot2", "cowplot", "biscale",
"grid", "lattice", "latticeExtra",
"maps", "mapproj", "sf", "showtext",
"tidycensus", "tigris", "rgeoda",
"usmapdata", "mapsf", "tmap"
), dependencies = FALSE)
# R version 4.2.0 (2022-04-22)
# Platform: x86_64-apple-darwin17.0 (64-bit)
# Running under: macOS Big Sur/Monterey 10.16
#
# Locale: en_US.UTF-8 / en_US.UTF-8 / en_US.UTF-8 / C / en_US.UTF-8 / en_US.UTF-8
#
# Package version:
# biscale_1.1.0.9000 blogdown_1.10 cowplot_1.1.1
# ggplot2_3.3.6 grid_4.2.0 knitr_1.39
# lattice_0.20-45 latticeExtra_0.6.30 mapproj_1.2.8
# maps_3.4.0 mapsf_0.5.0 rgeoda_0.0.9
# rmarkdown_2.14 sf_1.0-7 showtext_0.9.5
# tidycensus_1.2.2 tigris_1.6.1 tmap_3.3.3
# usmapdata_0.1.0
#
# Pandoc version: 2.18
#
# Hugo version: 0.101.07 参考文献
关于作者
黄湘云毕业于中国矿业大学(北京),多年 R 语言爱好者,与赵鹏、谢益辉一起合著了《现代统计图形》,统计之都软件工具栏目编辑,博客 https://xiangyun.rbind.io |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论