引言
如果此时你对何谓模型部署仍然一无所知的话,不必有任何焦虑的心情,带你入门正是本文的目标所在。请相信我,这篇介绍将会是十分新手友好的,怀着好奇心和耐心读下去,你也会对模型部署建立起清晰的认识。
模型部署是商业统计建模中极其重要的一部分,然而却往往被人忽视。读完本文,你将了解模型部署的基本概念与用途,学会如何在R语言环境中使用网络服务来部署上线一个模型,更多地,你的方法武器库中将会增添几柄利器: opencpu、fiery 及 plumber。话不多说,让我们开始吧!
引入模型部署
什么是模型部署
一句话概括,模型部署 是将一个调试好的模型应用置于生产或者类生产环境中,其意义在于处理预测新数据,为公司提供数据决策或者对接其他需求部门提供模型支持。我们先来看下面这幅数据科学项目开发流程图。

位于图片左边区域中的紫色圆圈中的文字,相信对大部分读者都不陌生。我们在学校中习得了很多关于数据科学模型、特征选择技巧及模型评价方法的知识,回想一下,在你过去大多数课程作业或是打比赛的经历中,完成了模型评价也就意味着项目宣告结束。然而在商业应用中,模型部署才标志着一个项目开发的阶段性结束。它的价值体现在两点:
- 赋予数据科学模型处理新数据的能力,可以是实时的流数据,或者是积累的批数据。
- 在实际应用场景中完成模型效果与性能的反馈,为模型调整提供依据,实现建模开发流程的闭环。
模型部署的手段
首先我引述其中几种常用的模型部署的手段,接下来我们将会介绍借助R中的网络服务这种形式来搭建一个线上的模型。
各种工具/工件(artifact)
有很多软件包均提供了将模型部署至小型终端设备上的功能。他们大都是将训练好的模型封装成一个对象并储存成自定义格式的文件,然后在相对应的平台或系统中加载调用这个对象,诸编程平台也大都有相应调用接口。 PMML (Predictive Model Markup Language) 是其中最常用的一种,它适合应用在实时、大规模数据量的场景。而在深度学习方面,TensorFlow 社区开发的 Tensorflow Lite 工具能翻译转换 tensorflow 预训练模型至 TensorFlow Lite 文件格式,然后用其他的接口来调用模型文件实现部署。除此之外还有一些其他的工具,可以参考R官网的 任务视图之模型部署部分,这里不再一一赘述。
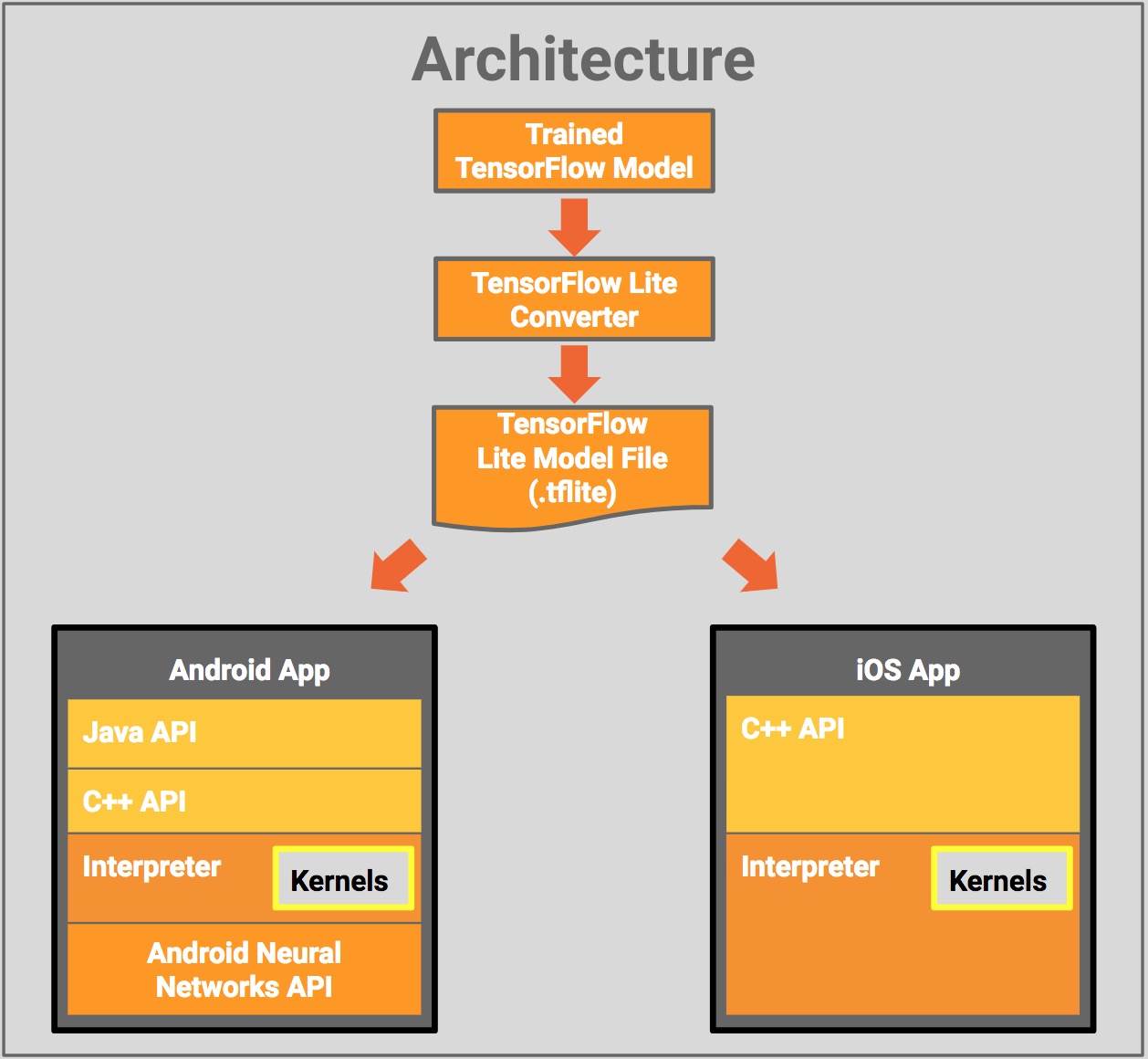
注: 图片来源自 tensorflow 官网
云/服务器
这种方式通过在服务器上开启一个服务的方式来部署模型,也是本文着力介绍的。主流的编程语言都有处理网络服务的功能,在 Python 中可以用 httpserver、flask、django 等搭建网络框架来部署;而 R语言做网络服务的包也不止一个,诸如 plumber、fiery、opencpu等。条条大路通罗马,本文不会对编程语言的选择提供任何建议。
既然是本文重点介绍的方式,不妨多啰嗦两句。
用网络服务做模型部署,将划分出线上与线下两个环境。线下环境是单机环境,用以做一些探索性或者验证性的分析,包含了分析建模的每一个步骤:特征工程、模型选择、模型评价、参数调节等
而线上环境则是生产环境,是把线下调整好参数的模型传至线上对新搜集的数据进行实时反馈。其背后的原理是借助 get&post 方法把特征字段传递给 web 服务器,服务器将会用封装好的模型预测并返回参数数值。对 get&post 不熟悉的可以参考 这个教程。
离线部署
这种方式相对来说就比较稀松平常了。问离线部署共分几步?答:共分三步。写好模型脚本 xx.R 或 xx.py;把累积的新数据下载下来;执行 Rscript xx.R 或者 python xx.py。完事儿~
闲话流数据
前文说到模型部署的一大价值便在于它赋予了数据科学模型处理新数据的能力,而很多新数据通常是实时采集的流式数据。而在我看来,对于流式数据的陌生也是大部分同学在校期间对模型部署接触不多的一大原因,或者与数据采集环节的遥远导致我们把大部分的精力都投入在如何用模型把面前样本数据中的模式挖掘出来。在这种场景下,数据是固定的,被存放在.csv或者各式各样的文件中。
让我们的思路再向前推移一步,用以存放数据的各种数据库或者数据文件是像蓄水池一样逐渐蓄满了被传递进来的数据,而这些数据均是经过一定的技术手段实时采集而来。那么,对于新的观测,一个部署在生产环境中的模型便可以实时地处理预测这些数据:比如互联网金融公司便可根据一个新申请的用户提供的个人信息来预测这名用户的信用评分,垃圾过滤系统也可以获取实时的邮件内容来判断这是否是垃圾邮件。
实战环节
得益于 RStudio 开发的工具包 httpuv,在 R 语言中处理 http 以及 Websocket 请求变成了现实,基于此工具包二次开发的框架 opencpu, fiery 和 plumber 提供了在线模型部署的解决方案,下面我们一一介绍:
场景实例:
我们演示的场景为垃圾邮件拦截,数据来源自 ElemStatLearn 包 spam 数据集。把问题拆解为以下四个步骤来模拟实际生产环境。
- 根据线下数据训练模型
- 从线上 MySQL 数据库中获取新数据
- 将数据传递至部署在web服务器上的模型并返回预测值
- 使用预测值来决策
首先我们进行一些准备工作:
- 安装所需要的程序包
Pkgs <- c('opencpu','fiery','plumber','xgboost','glmnet','ElemStatLearn','RMySQL')
lapply(Pkgs, function(pkg) {
if (system.file(package = pkg) == "") install.packages(pkg)
})
- 使用线下数据训练模型并保存,留待正式部署模型时使用。
library(xgboost)
library(glmnet)
library(ElemStatLearn)
x = as.matrix(spam[, -ncol(spam)])
y = as.numeric(spam$spam) - 1
xgbmodel = xgboost(data = x, label = y, nrounds = 5, objective = 'binary:logistic')
# 这里模型保存的路径可以自己设置
save(xgbmodel, file="../xgb.rda")
glmmodel = cv.glmnet(x = x, y = y, family = 'binomial')
save(glmmodel, file="../glm.rda")
opencpu
opencpu包在这三者中是发布最早的,包作者在2013年9月CRAN上发布了第一版。这个包的特点是 API文档示例详尽,并且提供了方便测试的图形化界面工具。
实现步骤
使用 opencpu 做模型部署遵循以下一般的开发流程:
- 把要上线的功能写个 R 包
- 编译安装 R 包
- 开启 opencpu 的服务器部署模型
- 连接该端口
STEP 1
定义函数逻辑,即从数据库中提取数据并用 xgboost 或者 logistic 模型预测,编写函数 getdata, xgbpred, linearpred 并把函数保存为 PredData.r。
## getdata: 从数据库中提取垃圾邮件数据
## params:
## id: 邮件id
getdata = function(id = 1){
# 这里spam_mail是MySQL数据库中已经建好的一张表
con = dbConnect(MySQL(),user = 'username',password = '123456',dbname = 'spam_mail')
sqlquery = paste0('SELECT * FROM spam WHERE id = ',id)
res = dbSendQuery(con, sqlquery)
data = dbFetch(res, n=-1)
z = unlist(data[,-1])
# 清空con的查询结果并关闭连接
dbClearResult(dbListResults(con)[[1]])
dbDisconnect(con)
return(t(as.matrix(z)))
}
此处模拟的情景是从MySQL数据库中提取数据,需要在本机上配置MySQL或者连接一个远程的MySQL数据库,具体的配置过程从略。
xgbpred = function(id = 1){
# xgbmodel与glmmodel是前面保存的xgb.rda与glm.rda,采用了默认加载的方式
v = xgboost:::predict.xgb.Booster(object = xgbmodel, newdata = getdata(id))
v = as.character(v)
return(list(class = v,
id = id))
}
linearpred = function(id = 1){
v = glmnet:::predict.cv.glmnet(object = glmmodel, newx = getdata(id), s = "lambda.min", type = 'response')
v = as.character(v)
return(list(class = v,
id = id))
}
STEP 2
创建 R 包 SpamModelOpencpu 并编辑文档,下图是编译好的 R 包的介绍。
如果你对R包开发不熟悉,可以参考这个 教程 或是谢益辉大大在统计之都上的 旧文。
STEP 3
在 R 控制台里运行单机版的 opencpu 服务器。
library(opencpu)
ocpu_start_server()
输出:
[2018-05-23 19:24:58] OpenCPU single-user server, version 2.0.5
[2018-05-23 19:24:58] Starting 2 new worker(s). Preloading: opencpu, lattice
[2018-05-23 19:24:58] READY to serve at: http://localhost:5656/ocpu
[2018-05-23 19:24:58] Press ESC or CTRL+C to quit!
控制台的输出告诉我们服务已经在 http://localhost:5656/ocpu 启动了,接下来你可以用浏览器访问这个url,或者在控制台中 curl 一下 (我使用windows平台下的git bash,CMD 中输入的命令可能会有些差异)
curl http://localhost:5656/ocpu/library/SpamModelOpencpu/R/xgbpred/json -d "id=1"
{
"class": ["0.875068128108978"],
"id": [1]
}
至此就大功告成了,恭喜你得到了一个可用的搭建在本机web服务器上的机器学习模型。
fiery
当我们在搭建线上服务时通常会希望请求响应的时间会尽可能快,尽管 opencpu 提供了在R环境中做模型部署的一个不错方案,然而与接下来要登场的这两位主角相比,它在响应时间上相形见绌。接下来我所要介绍的是 fiery,包名的来历 十分有趣:
Q: Is this a competing framework to Shiny?
A: In a way, yes. Any package that provides functionality for creating web applications in R will be competing for the developers who wish to make web apps. This is of course reinforced by the name of the package, which is a gentle jab at Shiny.
fiery“热情似火”的使用者得以用复杂度换取服务的灵活性,可以在R代码中嵌编辑HTML代码来定制服务,因此相比于用法优雅“bling bling”发光的shiny,高度自由的fiery就像是摇曳的炽烈火苗(纯属个人解读)。闲言说罢,让我们来用fiery实现任务。
实现步骤
编写一个新的R脚本文件,命名为 SpamM.r。
STEP 1
首先要开启一个网络服务实例并设置ip地址、端口:
suppressPackageStartupMessages(library(fiery))
suppressPackageStartupMessages(library(RMySQL))
suppressPackageStartupMessages(library(xgboost))
# 开启一个网络服务实例
app = Fire$new()
# 设置ip 地址和端口号
app$host = "127.0.0.1"
app$port = 9123
STEP 2
启动服务并同时开启监听,同时加载训练好的储存在 model.rds文件中的 xgboost 模型。
# Step1:启动服务,开启监听
app$on("start", function(server, ...) {
message(sprintf("Running on %s:%s", app$host, app$port))
model <<- readRDS("model.rds")
message("Model loaded")
})
STEP 3
响应 http 请求,编辑函数定义对访问路径为 hello 或 predict 的请求的操作逻辑。
/hello页面:介绍页面/predict页面:输入id,返回预测值的页面。
app$on('request', function(server, id, request, ...) {
response = request$respond()
## Step3:获取请求的path,一旦判断为 /predict 则进行预测
path = get("url", envir = request)
message(path)
## 索引介绍页面
if (grepl("hello", path)){
message('Welcome to the online prediction page')
response = request$respond()
response$body = 'Welcome!\n Type the url according to the Email\'s data id \n
Example: 127.0.0.1/9123/predict?id=235'
response
}
if (grepl("predict", path)) {
message('predict data.')
##Step3.1 获取并解析query string,
##query期待处理为 id=##
query = get("querystring", envir = request)
message(query)
## 解析query, 大概传递的是类似这个:parseQueryString("?foo=1&bar=b%20a%20r")
## input 解析出来是 list 对象
input = shiny::parseQueryString(query)
message(sprintf("Input: %s", input$'?id'))
## Step3.2 定义获取数据的函数
## 这里模拟从线上MySQL提取数据的逻辑,传入待查数据的id
## 若id不存在,那么返回报错
getdata = function(id = 1){
con = dbConnect(MySQL(),user = 'username',password = '123456',dbname = 'spam_mail')
sqlquery = paste0('SELECT * FROM spam WHERE id = ',id)
print(sqlquery)
res = dbSendQuery(con, sqlquery)
data = dbFetch(res, n=-1)
z = unlist(data[,-1])
# 清空con的查询结果并关闭连接
dbClearResult(dbListResults(con)[[1]])
dbDisconnect(con)
return(t(as.matrix(z)))
}
## Step3.3 进入模型预测环节
## 声明返回 res 是一个 list,传递参数为 input$val
res = list()
res$v = xgboost:::predict.xgb.Booster(object = model, newdata = getdata(input$'?id'))
message(res$v)
response$body = jsonlite::toJSON(res, auto_unbox = TRUE, pretty = TRUE)
response$status = 200L
}
response
})
STEP 4
一切就绪,启动服务。
app$ignite(showcase=FALSE) # 启动服务
接下来保存上面的所有编辑,并在控制台中运行该脚本。在 Windows 的 CMD 或者 Mac OS/Linux 的 Shell 中,这并没什么不妥,然而如果你是在 Windows下使用的 git bash,就要输入 winpty Rscript SpamM.r
Rscript SpamM.r
如果出现以下信息,说明目前一切顺利。
Fire started at 127.0.0.1:9123
message: Running on 127.0.0.1:9123
message: Model loaded
那么下面就试试访问先前定义的hello页面,并按照hello页面的提示编写一条按照id查询的url。
curl --silent http://127.0.0.1:9123/hello
Welcome!
Type the url according to the Email's data id
Example: 127.0.0.1:9123/predict?id=235
$ curl --silent http://127.0.0.1:9123/predict?id=1
{
"class": ["0.875068128108978"],
"id": [1]
}
plumber
包的介绍
plumber 是要介绍的最后一个包。在我看来,该包的优势有以下几点:
- 响应速度很快。
- 学习曲线平缓,即便你是个缺乏http请求与html语言的知识的小白,这并不妨碍你入门使用这个包,当然如果是深度使用用户,还是要对该包的运行机制有所了解的。
- 最后一点,该包提供的用 bookdown 编辑的 学习文档 方便上手学习,相信很多人对一份简明的开源工具使用文档的必要性深有体会!
案例实现
下面讲一下plumber的实现步骤,并不涉及过多原理。简要来说,plumber 借助 endpoint 与 filter 这两个控件搭建一个可用的 http 服务。
在使用 plumber 实现我们识别垃圾邮件的案例中,我们需要使用 endpoint 来指明路由,后面跟随这个路由对应的R环境中的函数操作。 endpoint 的声明借由在脚本里函数的前面嵌入@来实现,比如下面这段代码我们定义了一个 get 方法,它的路由是 ./predict,当你访问并向该路由发送请求时,请求中的参数 id 将会被提取出来并被传递至下面的函数。函数同样是定义了从 MySQL 中按照 id 提取数据并加载入模型。
#' 对request提取用户id并做预测
#' @get /predict
function(id){
getdata = function(id = 1){
con = dbConnect(MySQL(),user = 'username',password = '123456',dbname = 'spam_mail')
sqlquery = paste0('SELECT * FROM spam WHERE id = ',id)
print(sqlquery)
res = dbSendQuery(con, sqlquery)
data = dbFetch(res, n=-1)
z = unlist(data[,-1])
# 清空con的查询结果并关闭连接
dbClearResult(dbListResults(con)[[1]])
dbDisconnect(con)
return(t(as.matrix(z)))
}
res = xgboost:::predict.xgb.Booster(object = model, newdata = getdata(id))
res
}
而 filter 控件则可以用来监听请求并返回请求的信息。比如下面定义的 logger,将会在开启服务后打印出每条请求的发送时间、方法、路径、HTTP代理等信息。
#' 监听请求
#' @filter logger
function(req){
model <<- readRDS("model.rds")
cat(as.character(Sys.time()), "-",
req$REQUEST_METHOD, req$PATH_INFO, "-",
req$HTTP_USER_AGENT, "@", req$REMOTE_ADDR,"\n")
plumber::forward()
}
至此我们便完成了一个轻便服务的代码部分,将上面这些内容保存为脚本文件service_plumber.r。接下来在R控制台里运行
# 你需切换工作目录至service_plumber.r文件所在位置
pr = plumber::plumb("service_plumber.r")
pr$run(port = 2018)
至此,服务已在设定的端口2018启动,接下来我们便可以用浏览器访问 http://localhost:2018/predict?id=1,或者在命令行中运行curl http://localhost:2018/predict?id=1 ,返回编号为1的邮件的预测概率。
curl http://localhost:2018/predict?id=1
{"id":["1"],"v":[0.8751]}
这是在我的电脑上开启服务后打印的两条访问记录。
2018-05-23 20:10:12 - GET /predict - curl/7.55.1 @ 127.0.0.1
2018-05-23 23:03:10 - GET /predict - Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36 @ 127.0.0.1 ```
响应测试
天下武功唯快不破,评价一个服务性能的重要标准就是响应时间,下面我们用 microbenchmark 包来测试下三个部署好的服务的响应速度。
microbenchmark::microbenchmark(system('curl http://localhost:5656/ocpu/library/SpamModelOpencpu/R/xgbpred/json -d "id=1"'))
microbenchmark::microbenchmark(system('curl 127.0.0.1:9123/predict?val=1'))
microbenchmark::microbenchmark(system('curl 127.0.0.1:2018/predict?id=1'))
测试结果可能会因机器而异,下面的结果显示opencpu搭建的服务响应时间最久,中位时长为1.809s,而另外两个R搭建的服务的响应时长都在200毫秒左右,差异不大。
expr min lq mean median uq max neval
system("curl http://localhost:5656/ocpu/library/SpamModelOpencpu/R/xgbpred/json -d \\"id=1\\"") 1472.951 1699.469 1779.102 1808.699 1830.126 2772.285 100
expr min lq mean median uq max neval
system("curl 127.0.0.1:9123/predict?val=1") 105.5705 206.5052 216.8306 212.6028 219.0965 639.1698 100
expr min lq mean median uq max neval
system("curl 127.0.0.1:2018/predict?id=1") 204.974 207.8494 214.0799 212.2421 216.8809 332.6163 100
小结
至此你已经完成了模型部署的入门训练,恭喜!最后考虑到响应测试与上手难度,我个人向你推荐 plumber 这个包。与此同时,一个悲喜交加的消息是R社区中今年又发布了一个用并行化来实现的网络服务包 RestRserve,其响应速度堪称秒杀 plumber,据说是后者的20倍,留待后话。
参考资料
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论